
智谱正式发布工业级语音合成系统 GLM-TTS,并在 Hugging Face 和 ModelScope 上开放模型权重。GLM-TTS 目前已开源,并上线智谱开放平台(bigmodel)、智谱清言、Z.ai。
🎤 GLM-TTS:3秒克隆音色,“有情有声”的工业级语音合成模型
智谱最新开源的 GLM-TTS 是一款面向工业级生产的 AI 文本转语音(TTS)模型。它在保证发音准确性(低错误率)的同时,实现了接近真人的情感表现力,大大降低了高质量语音合成的应用门槛。
1. 核心能力:极速克隆与双 SOTA 性能
GLM-TTS 的设计目标是让 AI 不只是“会说话”,而是“会表达”,核心体现在以下两点:
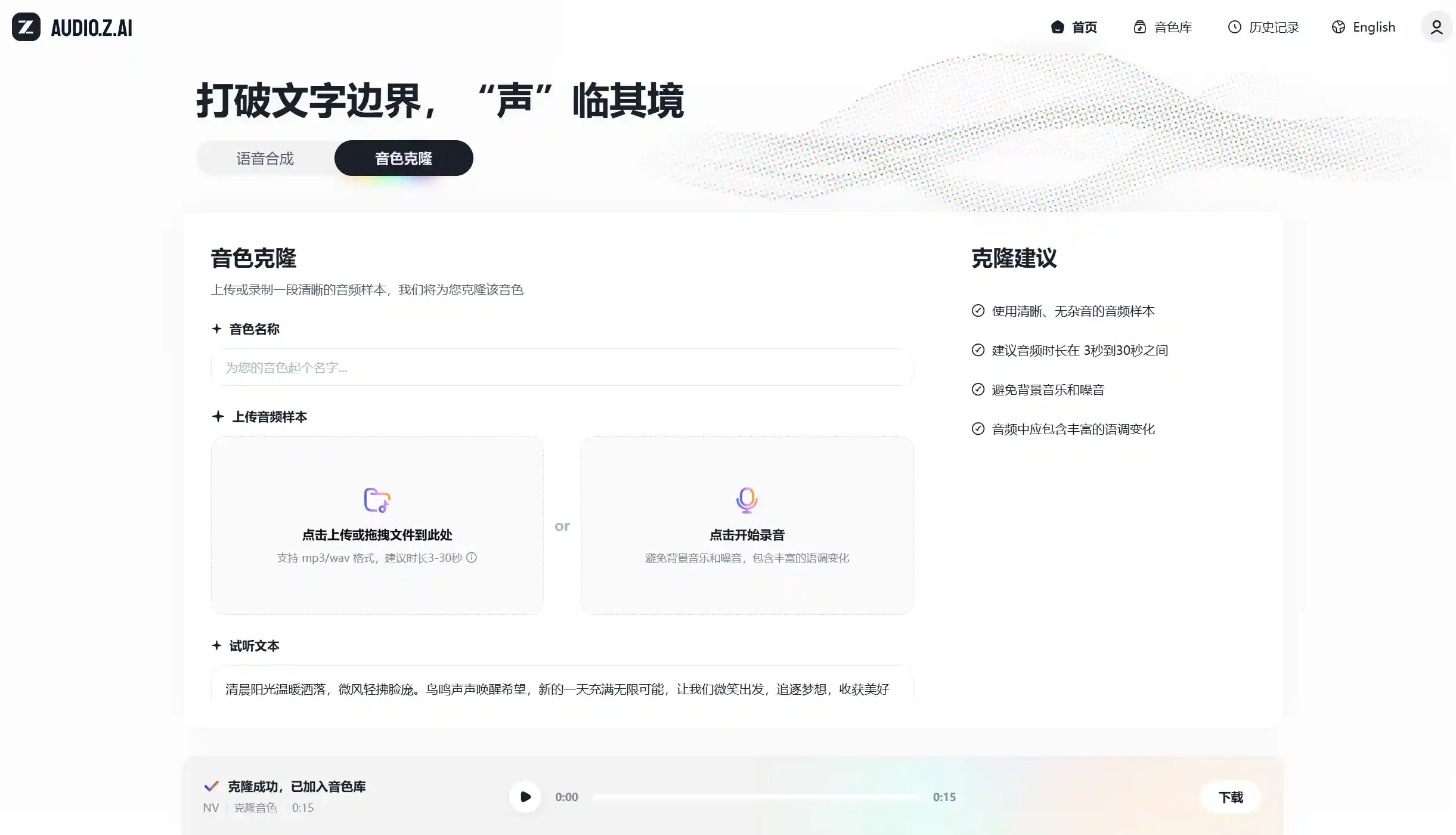
🚀 极速音色克隆
- 3秒复刻: 仅需 3秒(或至少 5 秒内)清晰语音样本,即可克隆说话人的音色、节奏、断句习惯甚至方言(如四川话)。
- 高相似度: 在保证极低错误率的前提下,保持了高音色相似度,兼顾“发音准确”与“音色还原”。
✨ 情感表达 SOTA (双重领先)
- 全情感覆盖: 模型突破了现有商用 TTS 多集中优化“Happy”情绪的局限,在 Happy、Sad、Angry 三类情绪上均取得了开源 SOTA 表现(平均情感得分 0.51)。
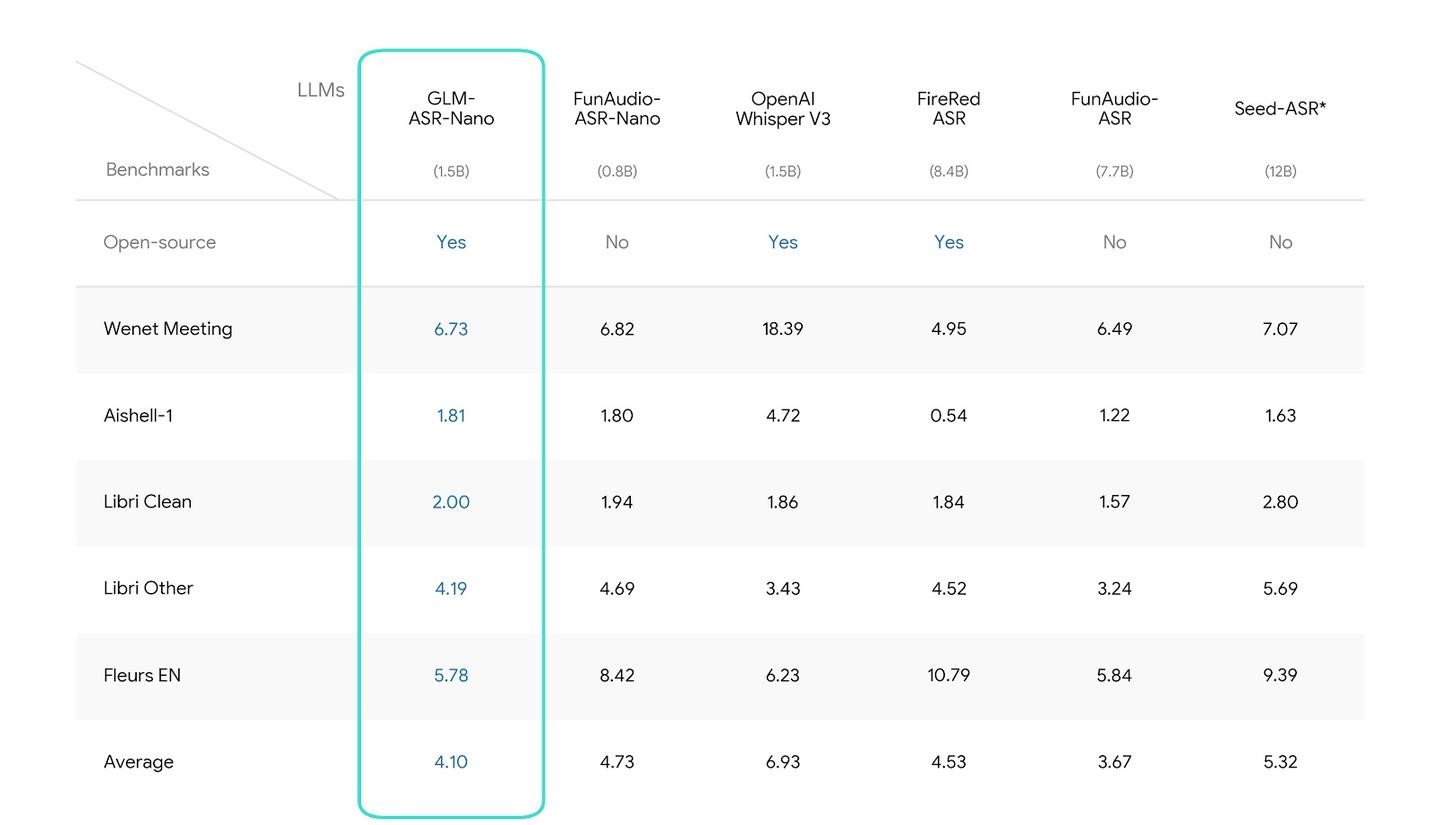
- 低字错误率: 在权威 seed-tts-eval 中文测试集上,引入强化学习后的 GLM-TTS_RL 字符错误率(CER)降至仅 0.89%,达到开源 SOTA。
2. 技术优势与低成本落地
GLM-TTS 采用高效架构,显著降低了训练和定制成本:
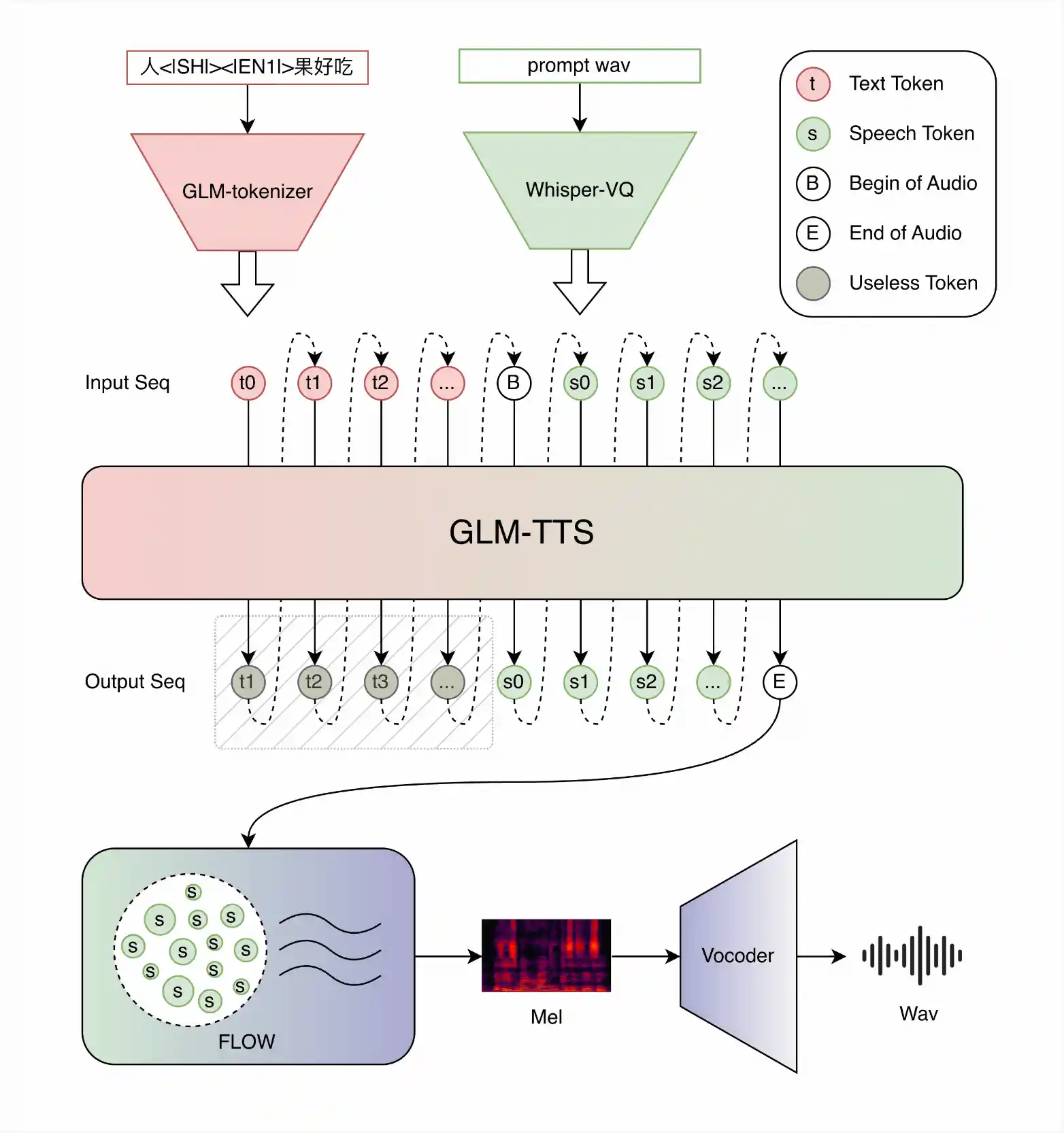
- 两阶段生成 + 强化学习: 采用 Text-to-Token → Token-to-Wav 的两阶段生成架构,并引入基于 GRPO 框架的多奖励强化学习(RL),有效提升了表达力,同时避免了奖励欺骗。
- 高效训练: 仅使用约 10 万小时训练数据(远低于行业主流),预训练仅需单机 4 天即可达 SOTA 准确度。
- 精品音色定制: 通过优化的 LoRA 微调范式,仅需微调约 15% 参数,单机 1 天即可完成高质量音色定制。
3. 生产级场景适配
GLM-TTS 已验证具备长期支撑行业级语音生产的能力,而非仅是 Demo 玩具:
| 场景 | 核心能力 |
| 教育评测 | 适配多音字、生僻字、公式符号,语气自然有耐心。 |
| 有声内容 | 支持多角色音色切换,适配长篇小说、纪实等不同文体的节奏与情绪。 |
| 智能客服 | 语气温和克制,可自然插入工号、物流进度等变量信息,降低机械感。 |
4. 开源与快速体验
智谱 GLM-TTS 已全面开源,并提供便捷的在线体验和 API 调用:
- 在线体验:
- Z.ai 官网: audio.z.ai(上传文本/语音 Prompt 生成专属声音)
- 智谱清言: App/网页版对话中体验多风格朗读与音色克隆。
- 开源资源: 模型遵循 Apache License。
- 企业级服务: 智谱开放平台提供 API 调用,价格仅为同类产品的 1/3 不到,具备高性价比。
GLM-TTS 的开源,标志着“高自然度、低门槛”的工业级语音合成技术正加速普及,为内容创作、教育、客服等各行业提供了强大的“有情有声”的 AI 语音能力。














