Nano Banana 最初于 2025 年 8 月中旬左右,神秘地出现在 LMArena 平台的图像盲测对抗系统(Image Edit Arena)中。它并非通过传统方式发布,没有官方公告或明确的开发者信息,而是让用户在盲测模型中随机遇到,并通过其出色的效果引起广泛关注。用户只需上传图片并输入文本提示,即可实现高质量的背景替换、风格转换和细节编辑。虽然尚未正式发布,且开发者尚未明确,但其出色的表现让许多人猜测它可能来自 Google
其主要依据包括:Google DeepMind 的负责人 Logan Kilpatrick 曾在 Google Pixel发布前发布过一条仅含香蕉表情的推文;Google 有使用水果或小吃名称作为内部项目代号的历史;其技术实力与 Google 的水平相符
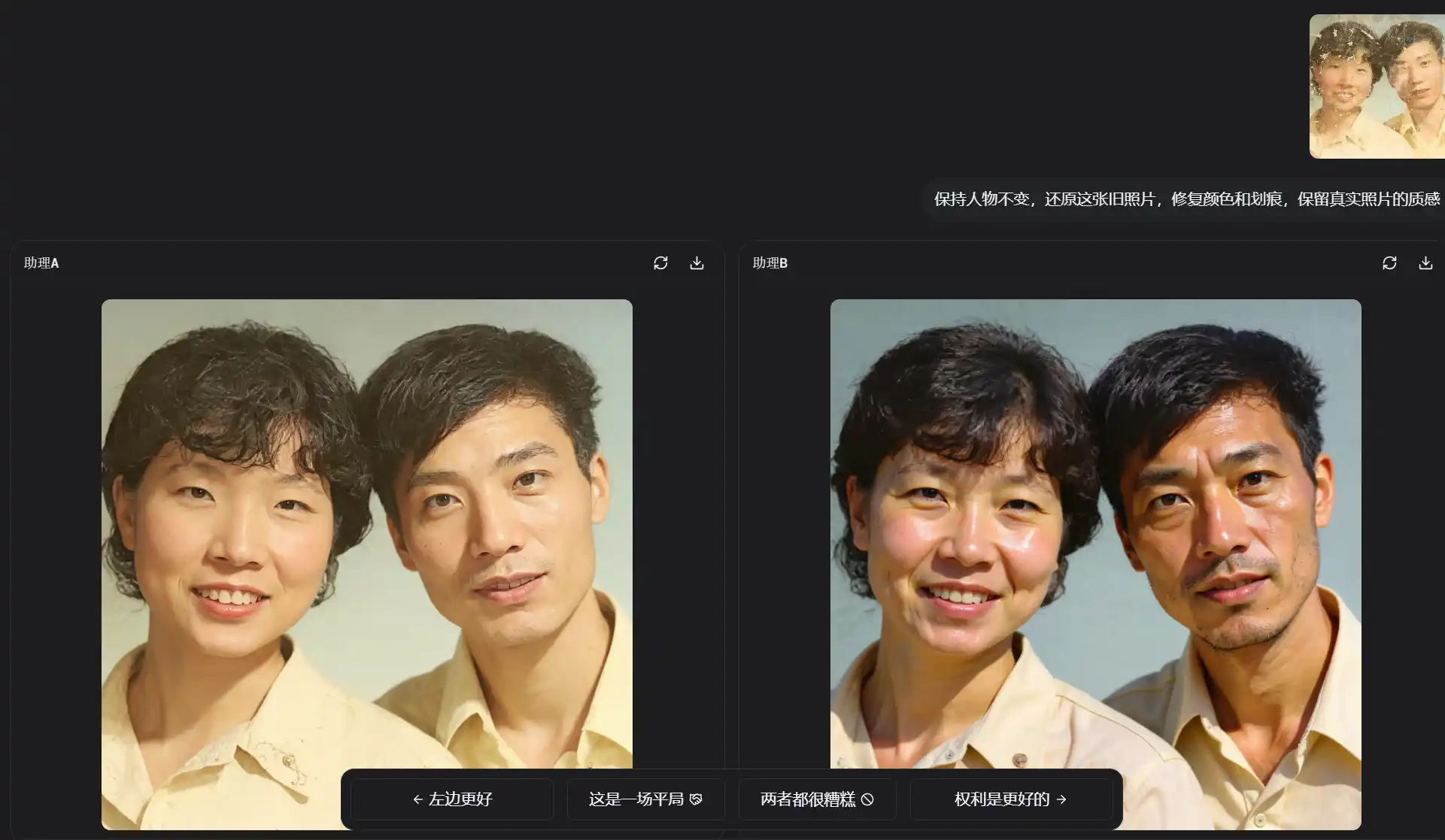
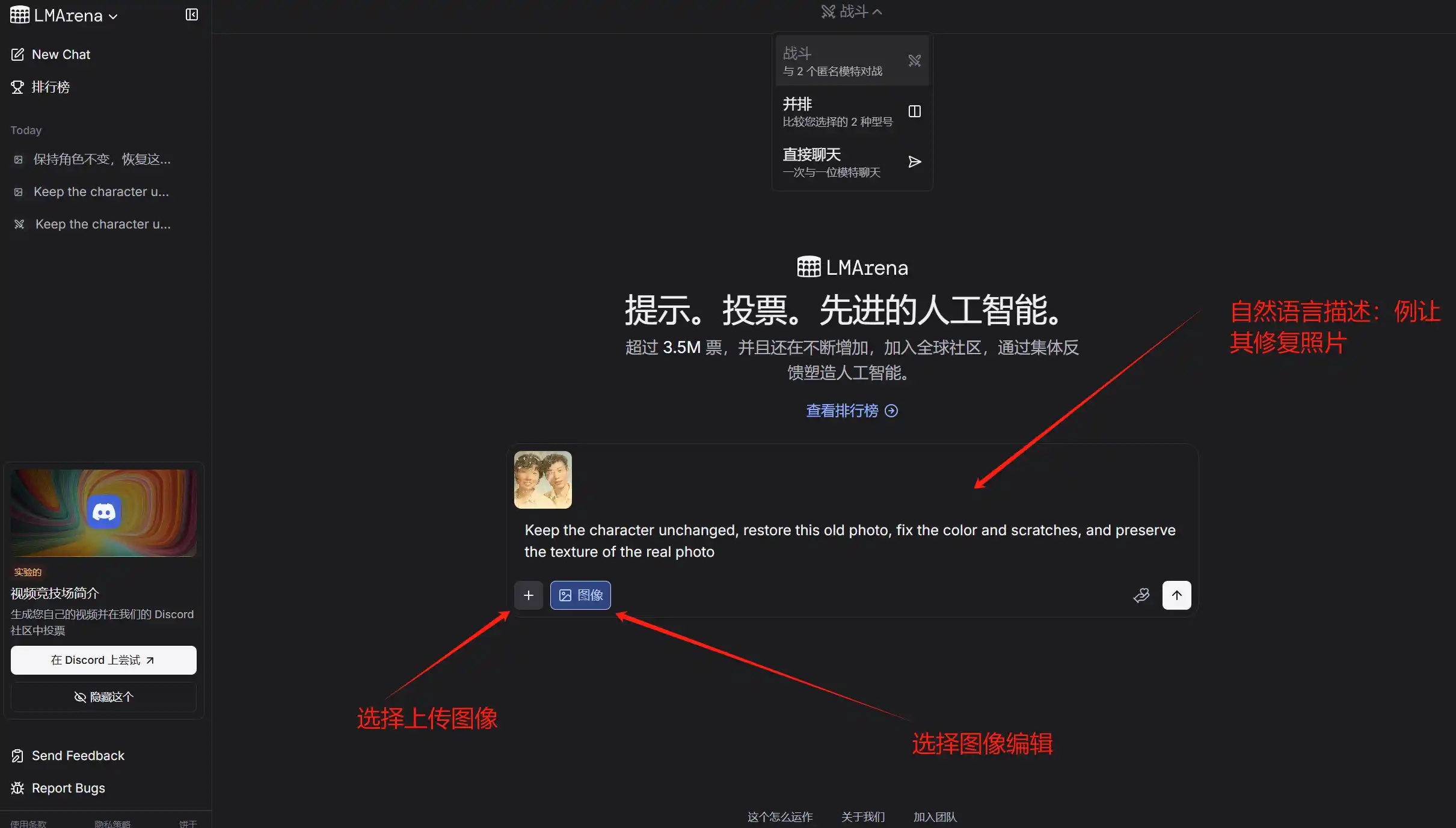
我们来真实感受一下他的编辑能力,修复老照片,右上角是原图,告诉他:保持人物不变,修复这张老照片,修复颜色和划痕,保留真实照片质感
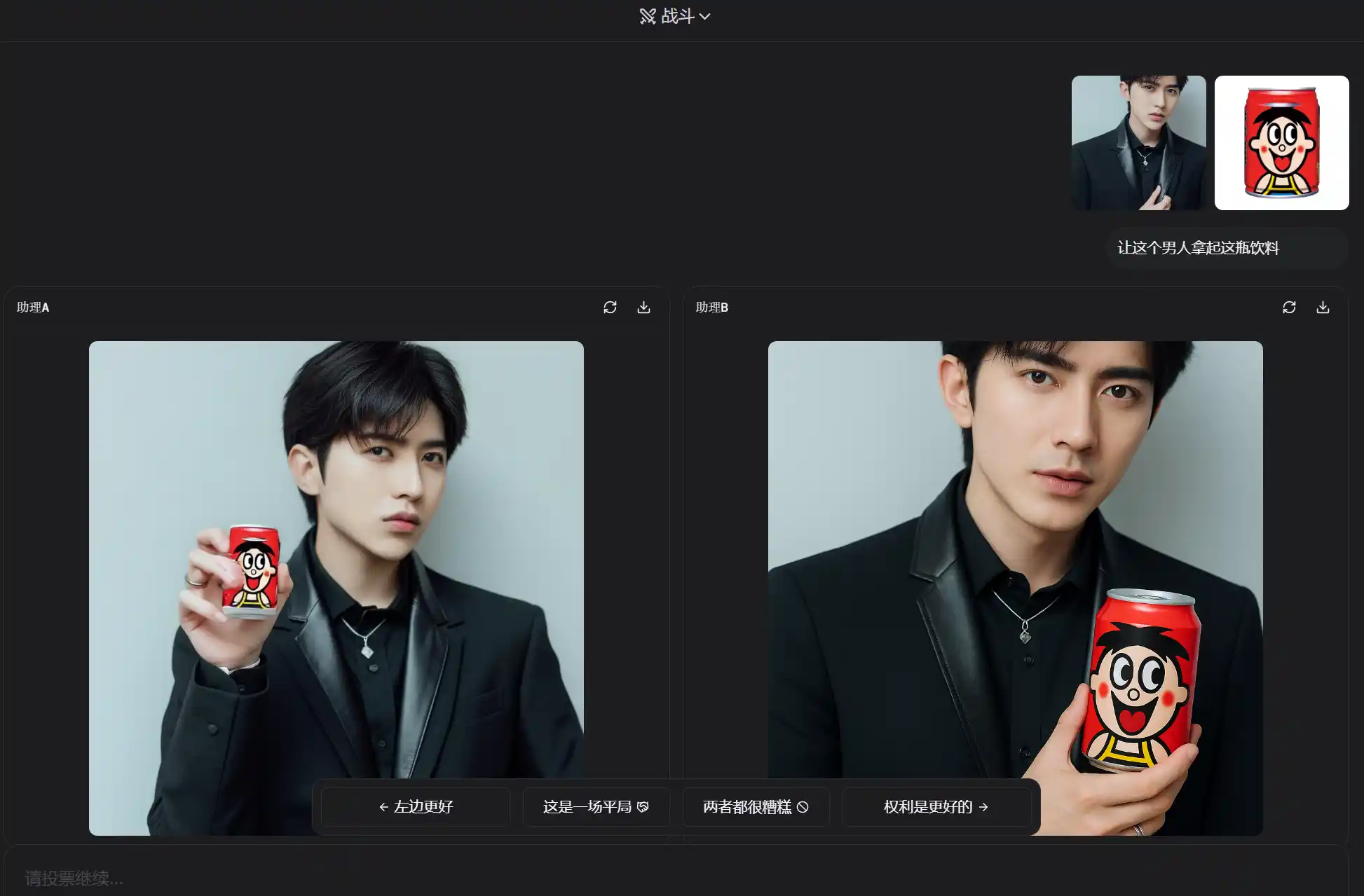
又或者进行多图融合:Let this man pick up this bottle of beverage
主要功能
Nano Banana 的核心功能是通过自然语言指令对图像进行智能编辑,以下是一些它的主要能力:
以下每个要点前都加了对应的小图标,便于快速浏览和记忆。
👤 人物一致性生成
这是 Nano Banana 最受赞誉的功能。它能够极度精准地保持原始人物的五官、神态、面部细节、身体姿态甚至嘴角弧度。无论进行何种编辑(如更换背景、改变表情或动作),生成图像中的人物形象都能保持高度一致,不会出现“换脸”的情况。
🌄 背景替换与融合
可以根据指令智能更换图片背景,并自动匹配新背景的光影、色调和环境氛围,实现无缝融合,效果真实自然,不像简单的贴图。
🎨 风格转换
支持将图像转换为多种艺术风格,如梵高油画风、赛博朋克、中国水墨画、水彩、素描等,同时在风格化过程中能很好地保持主体人物的特征不变。
🏃 动作迁移与姿势调整
根据文本提示词,可以调整图像中人物的姿势、手势或动作,并生成看起来非常自然的图像。
🔍 细节精准修改
能够对图像中的局部细节进行编辑,例如更换服装、修改文字内容等,并且过渡自然,违和感低。
💡 光影逻辑理解与调整
并非简单添加滤镜,而是能像在三维空间中一样重新计算光源和阴影,使编辑后的场景符合物理光照规律,例如正确调整物体影子的方向。
🧩 多图像合成与编辑
能够处理多张输入图像,例如将两个不同图片中的人物合成到同一个场景中(如让两个人在拳击擂台上搏击),并保持极高的真实感和协调性。
使用攻略
目前体验 Nano Banana 的主要途径是通过LMArena(免费)平台,但鉴于网络限制,这里整合了一下目前支持调用Nano Banana各大平台:
LMArena:https://lmarena.ai/(魔法,加州大学伯克利分校 SkyLab 团队创建的社区驱动型大型语言模型评测平台)
Gemini:https://gemini.google.com/app(魔法,免费,但限制额度)
AI Studio:https://aistudio.google.com/(魔法,开发者首选,功能最全面)
一些三方平台
Lovart:https://www.lovart.ai/(全球首个设计智能体)
椒图:https://www.jiaotuai.cn/(国内某agent团队开发,目前推广阶段免费用)
DeepSider:https://deepsider.ai/zh(一个浏览器插件,可以调用大部分大模型)
nanobananafree:https://nanobananafree.ai/(免费无限次免登录)
Fal.ai:https://fal.ai/login(免魔法,大模型平台)
modelscope:https://www.modelscope.cn/studios/AI-ModelScope/nano_banana_demo(模型平台,免魔法)
ZenFeed:https://image-generation.zenfeed.xyz/(免登录,免魔法)
OpenRouter:https://openrouter.ai/chat?models=google/gemini-2.5-flash-image-preview:free
huggingface:https://huggingface.co/spaces?q=nano-banana(大模型平台,很多网友开放的API空间免费用)
模型优势对比
Nano Banana 在与其他主流图像模型的盲测对比中,展现出了一系列显著优势:
| 特性 | Nano Banana | 其他主流模型 (如 Flux, Qwen, Gemini 等) |
|---|---|---|
| 人物一致性 | ⭐⭐⭐⭐⭐ 极强,能保持细微面部特征 | ⭐⭐⭐ 通常较好,但可能丢失细节或不一致 |
| 光影处理 | ⭐⭐⭐⭐⭐ 重新计算光影,符合物理规律 | ⭐⭐⭐⭐ 可能更像添加滤镜,逻辑偶尔有误 |
| 图像真实感 | ⭐⭐⭐⭐⭐ 照片级逼真,”AI 味”很淡 | ⭐⭐⭐ 可能呈现蜡质化或明显人工痕迹 |
| 提示词遵循 | ⭐⭐⭐⭐ 非常准确 | ⭐⭐⭐ 表现良好,但复杂指令可能出错 |
| 复杂编辑能力 | ⭐⭐⭐⭐ 擅长多步骤、多图像合成 | ⭐⭐⭐ 可能难以处理复杂合成 |
| 风格转换 | ⭐⭐⭐⭐ 自然,能保持主体特征 | ⭐⭐⭐ 效果不错,但可能改变主体 |
其技术架构据悉可能基于多模态扩散 Transformer (MMDiT),并采用了视觉自回归建模与传统扩散过程的结合。这使得它生成图像时并非从纯噪声开始,而是先生成一个结构化初稿再迭代优化,从而提高了生成速度和复杂场景的连贯性
相关链接
- LMArena 平台(主要体验渠道):https://lmarena.ai/?chat-modality=image8
- TechEblog 上的介绍文章:https://www.techeblog.com/nano-banana-ai-image-generator/9
- Geeky Gadgets 上的介绍文章:https://www.geeky-gadgets.com/nano-banana-ai-image-editor/2