LMArena(原名 Chatbot Arena)由加州大学伯克利分校团队发起,秉持“是骡子是马,拉出来遛遛”的理念,打造了一个全球范围内的大模型匿名对战平台,让模型在真实用户面前一较高下。
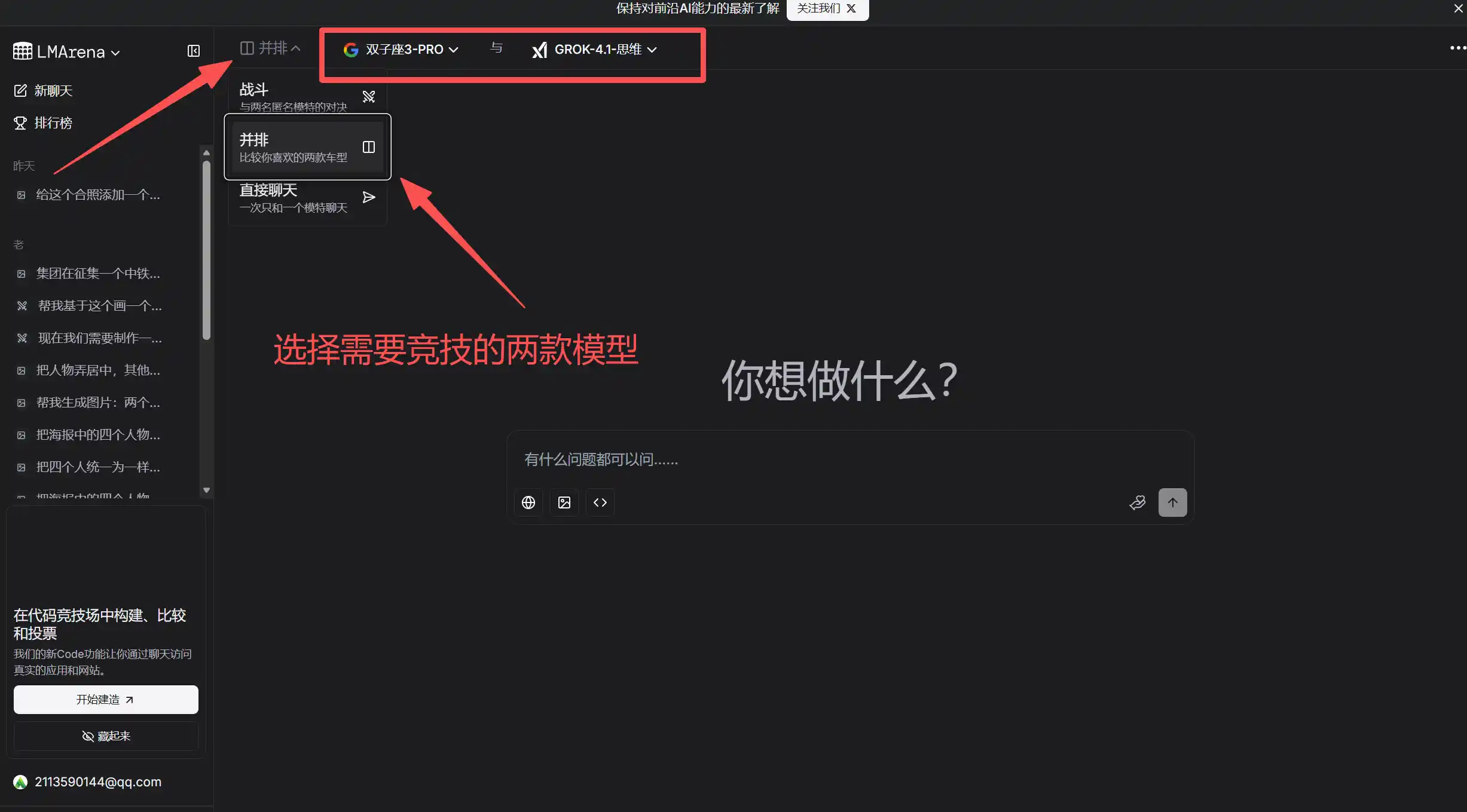
二、评测范式革新
- 摒弃传统指标:传统自动评测指标如 BLEU、ROUGE 等,虽高效却难以衡量模型的创造力、逻辑严谨性、安全性等主观体验。LMArena 采用“人类反馈驱动的对比评测”,将评判权交还给真实用户。
- 盲测机制:用户随机与两个匿名模型(仅显示为“模型 A”和“模型 B”)互动,基于回答质量投票,有效避免品牌效应等偏见,确保评测纯粹性。
三、核心功能
- 匿名盲测对战:用户向两模型提问,比较回答质量、相关性、创造性等,投票选出优胜者,或选择“平局”“都不好”。
- 埃洛评分系统:借鉴国际象棋的 Elo 评级系统,战胜高排名模型得分更多,输给低排名模型扣分也多,使排行榜极具动态性和参考价值。
- 实时动态排行榜:平台依据用户投票实时更新模型的埃洛积分,用户可直观了解各模型相对实力及排名变化趋势。
- 多样化模型参与:涵盖国际顶尖模型(如 GPT-4、Claude 等)及部分中国模型,为模型间横向比较提供平台。
- 细分领域排行榜:除总榜外,还计划推出代码、数学、创意写作等细分领域榜单,并公开部分匿名对话历史,助力深入分析模型表现差异。
四、优势与独特性
- 公正去偏见:盲测机制剥离模型品牌外衣,让评测回归模型实际表现。
- 全面评估维度:综合考量语气、个性、幽默感等难以量化的用户体验因素。
- 结果可信度高:排行榜分数源于成千上万真实用户交互选择,汇聚群体智慧,公信力远超单个机构评测报告。
- 动态实时更新:快速响应模型迭代,新模型崛起或旧模型改进都能及时反映在排名上。
- 开发者友好:为模型开发者提供实战检验场,助其发现模型不足,明确优化方向。
五、与中国模型的关联
尽管 LMArena 以全球用户为主要服务对象,评测侧重英文语境,但中国模型亦有机会参与。例如,若中国模型在平台上取得优异成绩,将彰显其国际竞争力;同时,平台积累的海量用户偏好数据,也为全球模型优化提供宝贵参考,间接助力中国模型迭代升级。
六、总结
LMArena 代表了一种崭新、民主化的大模型评估范式,将评判权从少数专家扩展到广大用户。于用户,它是强大的选型工具;于开发者,它是残酷的练兵场;于行业,它是照亮技术发展路径的明镜。随着参与模型增多、用户基数扩大,LMArena 生成的人类偏好数据,将驱动下一代大模型向更智能、更有用、更安全方向演进,有望成为衡量大模型实力的“行业金标准”之一。