你一定也很苦恼现在AI生图没有办法进行详细图层单独修改,那么分享给你一款Comfyui插件See-through,也可以在WebUI使用
See-through 是一个将单张静态动漫插画自动转换为可交互 2.5D 模型的技术框架,能够将静态动漫插画自动转换为可操作的2.5D模型。可将单一图像分解为完全上色、语义上不同的图层,并推断出绘图顺序——最多可达23层,包括头发、面部、眼睛、服装、配饰等。

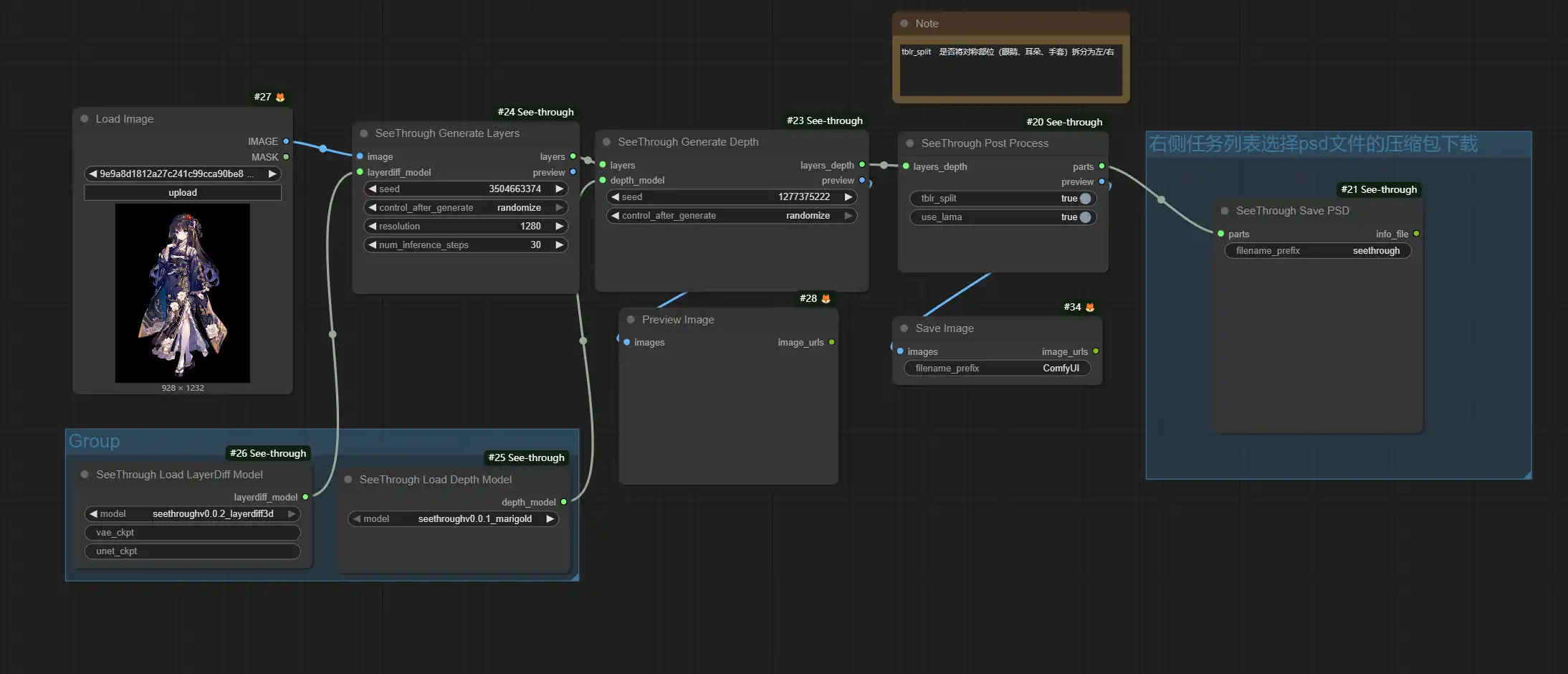
其核心流程遵循”解构-修复-分层”的三阶段:
🔹智能透明图层生成 基于 SDXL 扩散模型,能精准识别动漫角色的语义结构(如头发、衣物),更能生成带 Alpha 通道的透明图层。区别于传统分割模型仅做”前景/背景”的二元判断,它能智能补全被遮挡区域的几何轮廓——例如透过发丝推断完整的头部形态。
🔹动漫深度估计 专为动漫视觉风格微调的深度预测模型,为每个像素生成伪深度值。这些深度信息精确约束图层的空间层级关系,确保视觉逻辑合理(如刘海层永远置于眼球层之前,衣领层覆盖于脖颈层之上)。
🔹细粒度语义分割 采用 Segment Anything Model (SAM) 实现身体部位的像素级解析,支持 19 类细粒度属性标注:
- 头部区域:前发、后发、侧发、眼睛、眉毛、嘴部、脸颊
- 肢体躯干:躯干、手臂、手部、腿部
- 服饰道具:上衣、裙裤、配饰、武器及其他手持物品
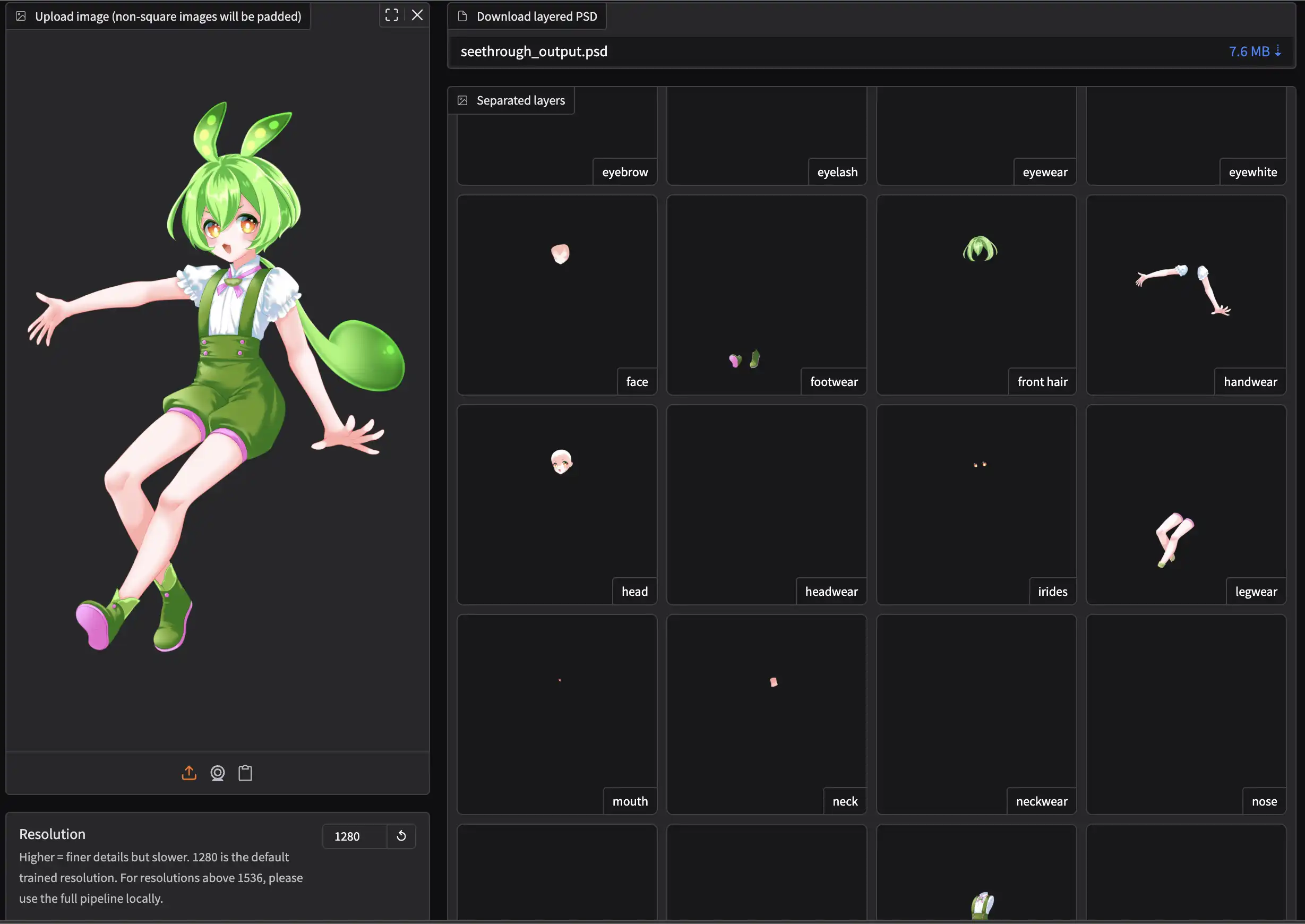
目前支持AI分层生图的其他工具例如lovart、Qwen-Image-Layered、Adobe Firefly 都是原生分层
体验地址
qwen:https://zhuanlan.zhihu.com/p/1986552580889932769
lovart:https://www.lovart.ai/zh
那么对于已经做好的图如何进行分割分层直接到处PSD源文件,建议用see-throug,不过他比较针对平面人物画
see-through:https://github.com/shitagaki-lab/see-through
这样如果你注册HuggingFace,每天应该能运行1-2次PSD提取(每次约2-3分钟,分辨率为1280),可以在线试试
地址:https://huggingface.co/spaces/24yearsold/see-through-demo
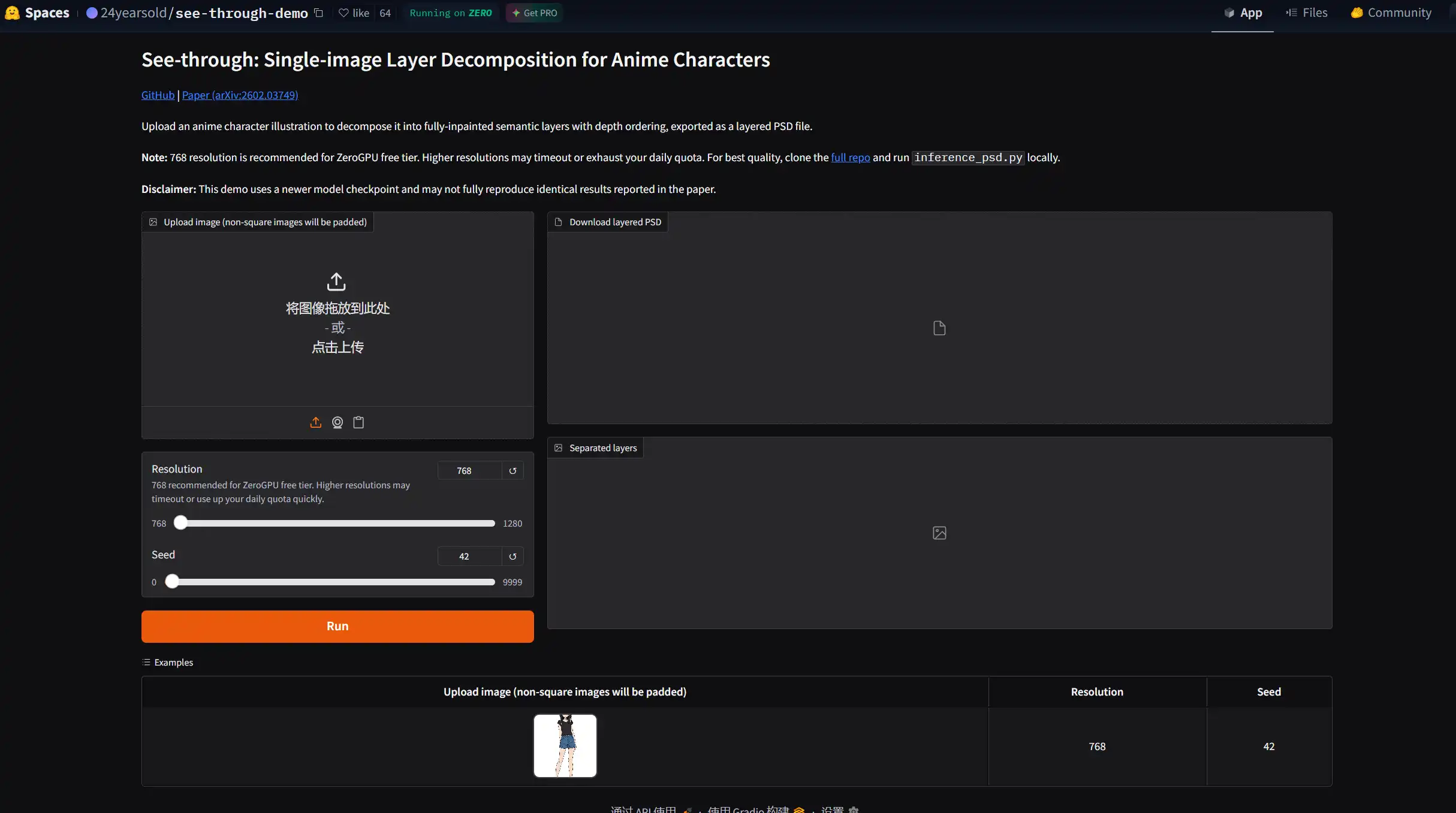
或者在RunningHub ComfyUI Workflow在线运行使用