北京时间9月13号凌晨1点左右,OpenAI毫无征兆的公布了他们最新一代模型:o1 preview(预览版)、o1 mini
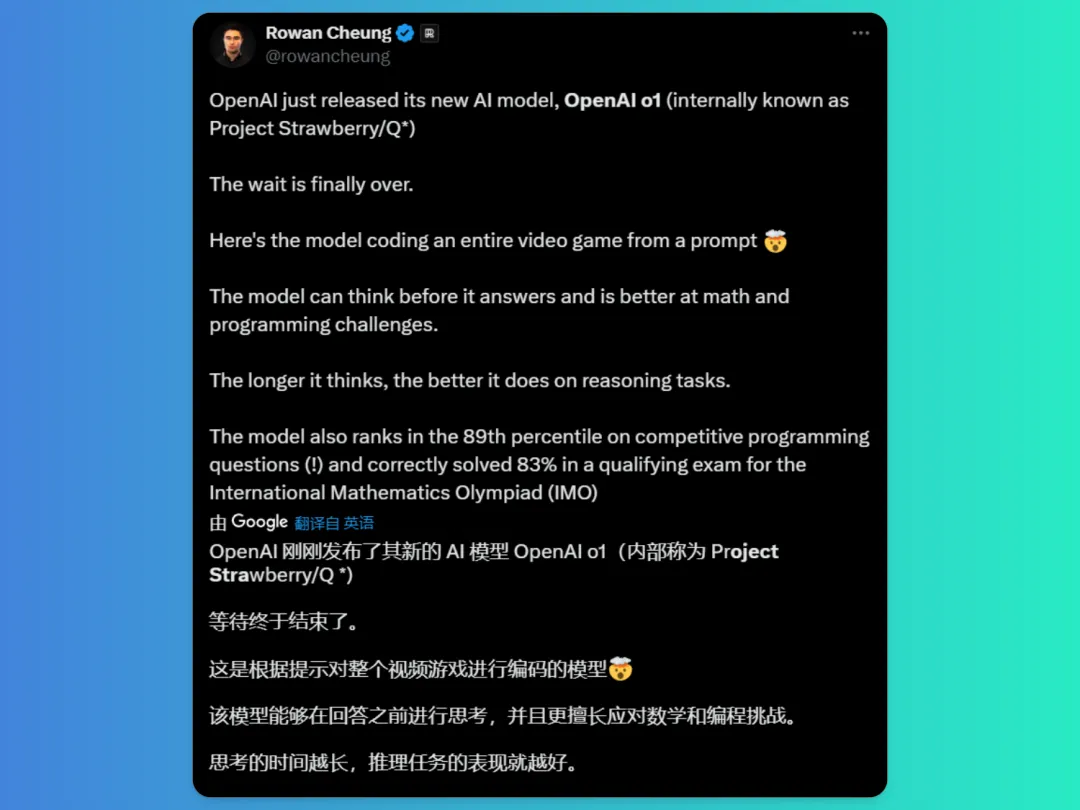
传说中的“草莓”,迄今为止OpenAI最好的推理模型,他来了!
最强的升级点是:面对一个问题时,o1会先像人类一样思考,尝试各种策略,并不断修复自己的错误,最终给出答案
同时,OpenAI 为此在某管上立马一次性发布了13个Demo视频,无论是计数、编写代码、数学计算和逻辑推理等功能,o1模型都得心应手
此次公布的OpenAI o1模型最早可以追溯到代号为“Q*”的一款流传的内部模型,同时它也是前几天传得沸沸扬扬“Strawberry”的最早版本。
我们先回顾一下之前新闻报道中对“Strawberry”的描述:
在处理编程和数学难题方面,Strawberry 展现出了超越其他高端生成式AI模型的能力,包括OpenAI自家的GPT-4o。它还成功规避了那些常见于其他模型的推理错误。然而据透露,Strawberry的运行速度极为缓慢,且并非多模态版本。据一些消息来源称,该模型处理一个问题的耗时介于10至20秒之间
从OpenAI官网的信息来看,OpenAI o1的特点可以总结为:更大、更强、更慢、更贵
- o1 核心特点:OpenAI o1 模型在回复之前会花更多的时间思考。它们能够推理复杂的任务,并比以前的模型在科学、编程和数学领域解决更难的问题
比如,在一个让众多AI大模型犯错的问题:“单词Strawberry里面有几个r”,GPT 4o回答错误,那是因为像这样的模型是为了处理文本而不是字符而构建的
与 gpt 4 不同的是,它在输出答案之前开始思考这个问题。现在它输出答案,单词Strawberry中有三个 r,这才是正确答案
这个例子表明,即使对于看似无关的计数问题也有推理,内置模块可以帮助避免错误
- 版本:与之前不一样的是,OpenAI将计数器重置为 1,并将这个系列命名为“OpenAI o1”,且本次只是发布一个预览版本(preview),并未发布正式版本
- 基准性能:此次新模型在物理、化学和生物学的挑战性基准任务上表现得与博士生相似
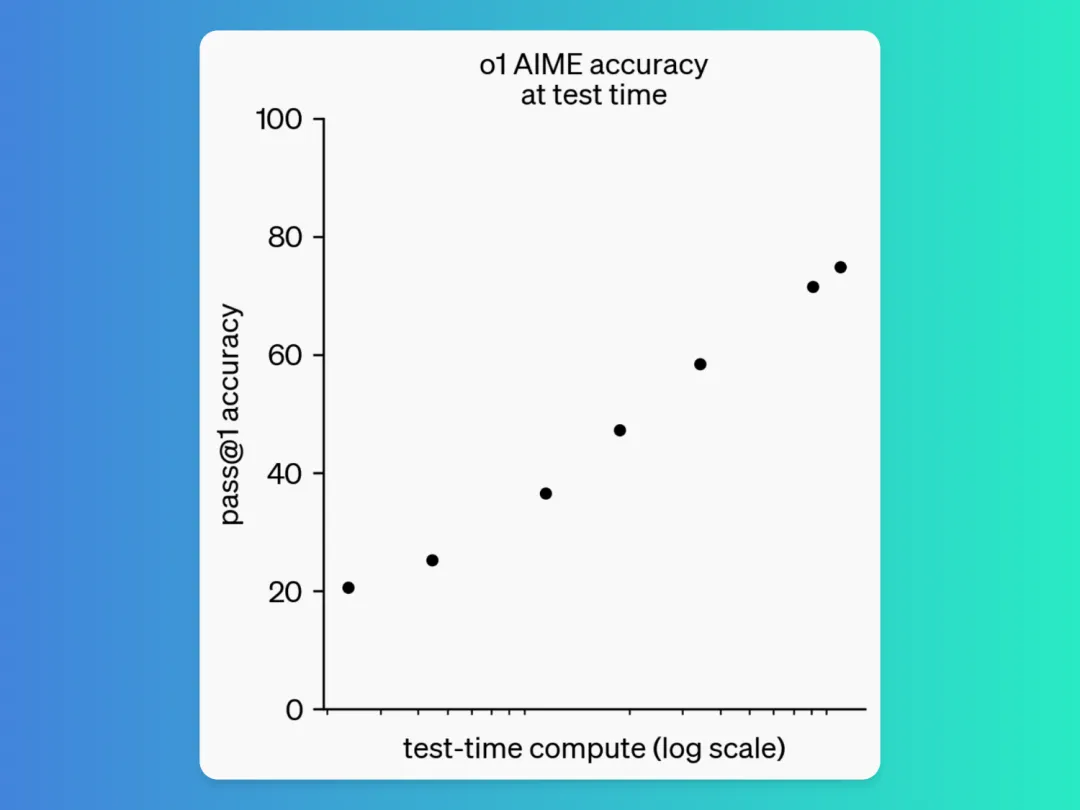
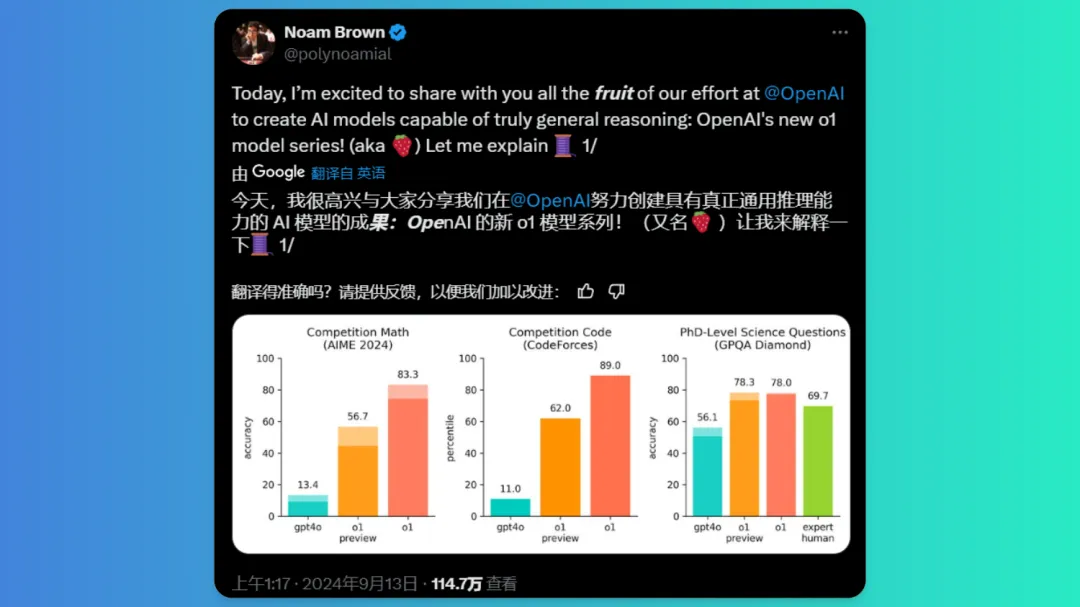
在2024年美国数学邀请赛(AIME)中,模型o1的准确率最高,达到了83.3%,其次是gpt4o,准确率为80%。在CodeForces编程竞赛中o1模型的表现最好,百分位数为89.0%,其次是gpt4o,百分位数为62.0%。在GPQA Diamond测试中o1模型得分最高,为78.3%,其次是gpt4o,得分为78.0%,把人类博士67.9%的准确率无情超越
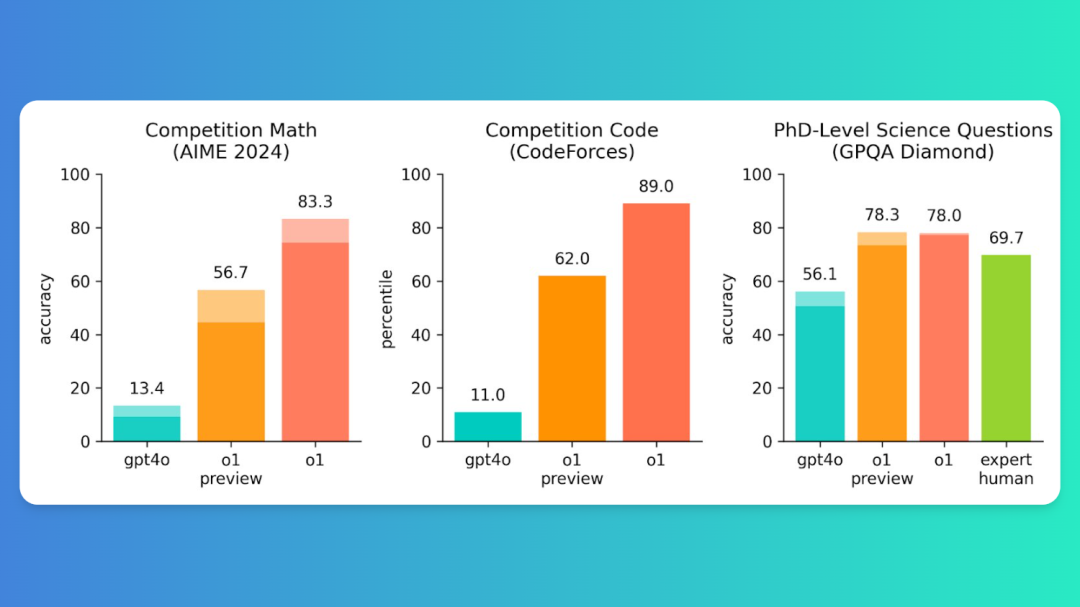
模型o1、o1 preview和gpt4o在2024年美国数学邀请赛(AIME)、CodeForces编程竞赛和GPQA Diamond中的表现
其中,2024年美国数学邀请赛(AIME)是属于美国数学竞赛中仅次于奥林匹克数学竞赛的比赛

同时,o1模型在多个领域和测试中都展现出了明显优于gpt4o的性能,无论是在科学问题、机器学习基准测试,还是在数理化生、法律经济各种专业考试中
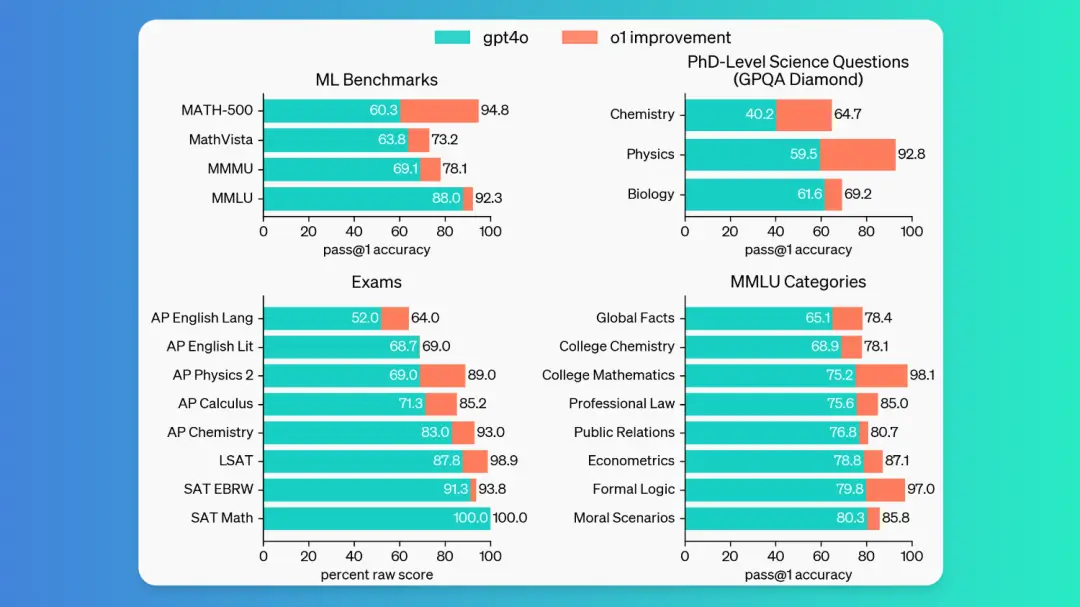
- 是否有多模态:作为早期模型,它还没有像GPT 4o一样拥有浏览网络获取信息和上传文件、图片的特性
- 价格如何:ChatGPT Plus 和团队用户现在可以开始在 ChatGPT 中访问 o1 模型。在模型选择器中,用户可以手动选择 o1-preview 和 o1-mini。每周的配额为 o1-preview 30 条消息,o1-mini 为 50 条消息
ChatGPT 企业版和教育用户将于下周开始访问两个模型。符合条件的开发者可以开始使用 API 原型设计,今天就可以使用两个模型,每分钟的速率限制为 20 次。OpenAI还计划将 o1-mini 访问权限带给所有 ChatGPTFree 用户
- 安全性:OpenAI的o1-preview和o1-mini通过链式思维推理显著提高了模型在安全性和鲁棒性方面的表现
- 禁止内容评估:o1-preview和o1-mini在标准拒绝评估和挑战拒绝评估中均表现出色,接近或超过了GPT-4o的表现。特别是在更具挑战性的挑战拒绝评估中,o1-preview和o1-mini显著提高了性能
- 偏见评估:o1-preview在偏见评估中表现优于GPT-4o,尤其是在选择非刻板印象答案方面。然而,o1-preview在处理模糊问题时表现较差,倾向于选择“未知”选项而非刻板印象答案