
一个基础的理解
行业大模型研发 可类比“做菜” ,找菜谱(行业案例调研及基模选型),备柴火(算力)、加工食材(主菜:基础大模型、数据;配菜:小模型、插件)、用炊具(AI工具集)
一些大模型、数据集工具
- 微调视频教程:https://www.bilibili.com/video/BV1djgRzxEts/
- 主流微调工具:https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
- 文本数据集生成工具:https://github.com/ConardLi/easy-dataset
- 模型评测工具:https://github.com/modelscope/evalscope
- 图像数据集标注工具:https://github.com/HumanSignal/label-studio
- Label-Studio:https://blog.csdn.net/qq_32323239/article/details/146150362
- Docker安装部署:B站教程:保姆级Docker安装+镜像加速 计算机系必备技能_哔哩哔哩_bilibili,在此之前需要安装:旧版 WSL 的手动安装步骤 | Microsoft Learn
一些关键概念的理解
- 泛化能力
大模型的泛化能力指的是模型在未见过的数据上表现的能力,即模型不仅能在训练数据上表现良好,也能在新的、未知的数据集上保持良好的性能。这种能力是衡量机器学习模型优劣的重要指标之一。数据集的选择与多样性、模型结构与复杂性、训练数据的质量与数量、模型训练方法、模型评估方法都是量化和评估大模型的泛化能力的一些指标
- 分词器、词表、词表扩充、词元
深度学习模型可以以图像、文本、语音等多种形式作为输入,第一步都是将任务相关信息 编码成计算机能够处理的数字形式。在大模型中,分词器就发挥着这样的作用,它可以将词元 编码成词表中的编号,从而作为大模型的输入。分词器拆分文本 → 词元映射到词表ID → 词表大小影响模型覆盖率和效率 → 扩充词表需适配新任务。
分词器(Tokenizer)作用:将文本拆分成词元(Token),并映射到词表中的数字ID,供模型处理。影响:决定文本如何输入模型,直接影响模型的理解和生成能力。
词表(Vocabulary)作用:存储所有可能的词元,是模型输入/输出的基础。关键问题:词表过小 → 大量生僻词无法识别(OOV问题)。词表过大 → 稀疏性增加,效率下降。
词表扩充场景:跨语言/垂类任务时,需加入新词元并微调模型,目标:提升模型对新词元的表征能力。
词元(Token):可以是单词、子词(如"un"+"happy")或符号。
分词策略:影响词表大小与压缩率(如BERT用WordPiece,GPT用Byte-Pair Encoding)。
压缩率(Token效率)定义:input_ids长度 / 原始文本字数,值越低效率越高。平衡点:词表增大到一定程度后,压缩率不再提升,需权衡稀疏性与效率。
- 大模型微调的损失函数
- 算力、算力
算力:指计算机系统在单位时间内能够完成的计算任务量,它涵盖了CPU、GPU、TPU等硬件,每秒能处理的数据量,通常以“P”(PetaFLOPS,即千万亿次浮点运算每秒)为单位来衡量,是评估计算机性能的重要指标。AI 算力单位:量级单位+每秒运算次数+数据类型
算法:算法是一系列解决问题的步骤和规则,用于特定问题的解决或任务的完成。它类似于烹饪食谱,提供了从原材料到成品的详细步骤。例如,程序员初学时接触的‘冒泡排序’、‘快速排序’、‘二分查找法’都是算法的典型例子。而在AI领域,算法更为复杂和高级,如决策树、线性回归、朴素贝叶斯等。总的来说,算法是处理数据并找出规律的工具。
- 预训练数据集
预训练数据集通常由多种来源的高质量文本构成,包括维基百科、图书、学术论文、网页爬取数据和开源代码等(如Common Crawl、GitHub),经过清洗和配比后形成大规模语料库(如The Pile、RefinedWeb);微调阶段则使用较小但标注精细的数据(如Alpaca、HelpSteer),通过人工反馈优化模型表现。
- 一体机
训推一体机是一种将训练与推理功能合二为一的AI计算设备,凭借高度集成、强大算力、灵活性、优化设计和扩展性五大特点,为大模型的开发和应用提供了高效支持。详细:训推一体机是什么?从原理到应用的全面解析-天下数据
- 思维链
2022 年 Google 论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中首次提出,通过让大模型逐步参与将一个复杂问题分解为一步一步的子问题并依次进行求解的过程可以显著提升大模型的性能。而这些推理的中间步骤就被称为思维链(Chain of Thought)。一个完整的包含 CoT 的 Prompt 往往由指令(Instruction),逻辑依据(Rationale),示例(Exemplars)三部分组成。
大模型的规划能力是大模型智能体的智慧基础。通过合理的任务规划,可以将复杂的任务 拆解为大模型能够理解和执行的小任务,并确保这些任务得以妥善完成。因此,规划能力在一 定程度上是大模型智能体的智能体现,决定了其效果的上限。随着其能力的提升,涌现 出了思维链这样的额外能力。正是依托于大语言模型的推理能力,智能体才能执行规划过程, 以此来应对和解决复杂问题。强大的逻辑推理是大语言模型“智能涌现”出的核心能力之一,好像AI有了人的意识一样。而推理能力的关键在于——思维链(Chain of Thought,CoT)。
CoT 的好处:增强了大模型的推理能力、可解释性、可控性、灵活性;相关文献参考:一文读懂:思维链 CoT(Chain of Thought)
- QPS、TPS、并发量、吞吐量
理解QPS、TPS、并发量、吞吐量_qps和吞吐量的区别-CSDN博客
- POC快速验证
AI PoC(人工智能概念验证,Proof of Concept)是一个用于验证人工智能解决方案可行性的小规模实验或原型。其主要目标是测试某个AI想法或技术是否值得进一步投入资源和时间。通过PoC,可以评估AI技术在特定场景中的实际效果,并为后续的全面部署提供依据。
- SFT监督微调
SFT(Supervised Fine-Tuning)是将预训练模型转化为实用AI助手的关键步骤;预训练阶段模型像博览群书但不求甚解的书生,只会死板背书,预测下一个token,海量知识但无法与用户指令适配。SFT转换通过有监督微调,教会模型如何使用知识指令微调训练模型的通用指令遵循能力。目标达成成为真正实用的AI助手,在多种任务上表现优秀的智能助手。
四种主要的有监督微调方法:指令微调对话微调领域适配文本分类
- 不收敛、欠拟合、过拟合、泛化能力
不收敛就是根本没学会。
欠拟合是指模型不能在训练集上取得好的结果(获得足够低的loss)。学会了点,但是也没学会。模型在训练集、测试集上表现都很差。
过拟合是指在训练集上表现很好,但是测试集上表现很差。简单来说,就是学过头了。比如说,学半天1+1=2然后只会这个了,到了1+2就不会算了。模型对训练集"死记硬背",没有理解背后的规律。
泛化能力,也就是指的AI对未知样本的推理、适应能力。泛化能力差是过拟合的直接表现。
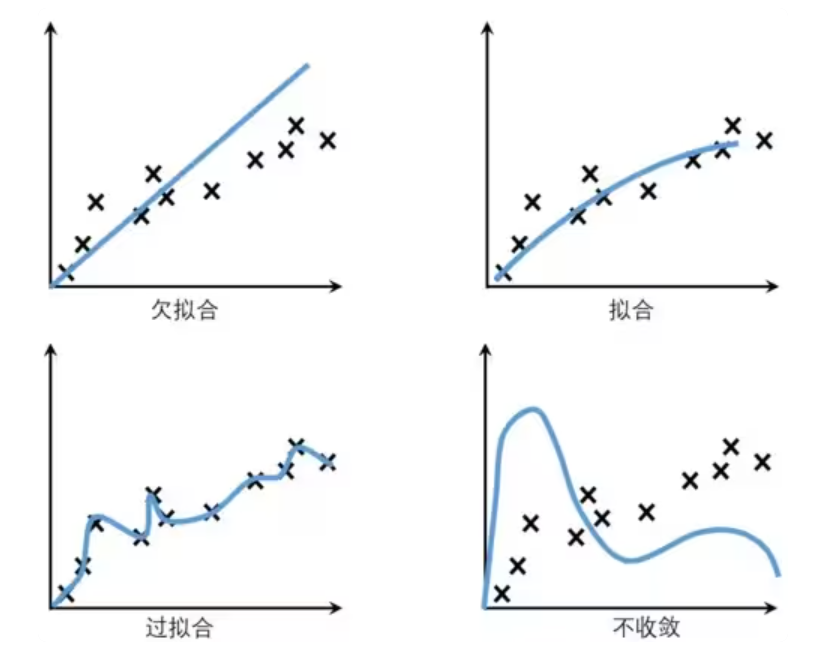
- 模型坍塌
模型坍塌:是深度学习和生成模型中常见的现象,指模型在训练过程中逐渐失去多样性和泛化能力,导致性能严重退化甚至无法继续优化。仅在合成数据上训练的模型可能会进入一个退化循环,生成缺乏新颖性和原创性的输出。这是因为这些模型越来越依赖自身的输出或类似系统的输出,导致对语言的理解趋于同质化且不够稳健。
性能退化:训练过程中,模型的准确率下降、损失函数发散或过拟合。生成模型(如GAN)中,生成器可能仅输出单一或重复的结果(如所有样本趋同于某个模式)。对比学习中,所有数据映射到单位超球面的同一常数点,失去多样性。
无法恢复性:即使调整训练策略,模型性能仍难以恢复到坍塌前水平.毕竟第一代大型语言模型是通过抓取互联网数据并使用人类反馈强化学习或者强化学习等技术微调.随着AI的普及,由AI生成内容的正在增加,导致LLM,可能不可避免地使用自身输出的内容进行训练.到2026年,90%的在线内容将有AI生成
参考文献:什么是"模型坍塌"及如何解决"LLM模型塌"? - 腾讯云开发者社区-腾讯云
- 知识蒸馏和模型量化
一、知识蒸馏:一种模型压缩方法,旨在将大型模型(教师模型)中的知识转移到较小的模型(学生模型)中。其基本原理是通过训练一个更小、更轻量级的模型来学习更大、更复杂的模型的知识。压缩已训练好的模型方法有知识蒸馏、权值量化、权重剪枝、通道剪枝、注意力迁移
二、模型量化:模型量化是将神经网络中的高精度浮点数转换为低精度表示的过程,目的是减小模型体积并提高推理速度,同时尽可能保持模型精度。可以形象比喻为无损音乐压缩为MP3等格式,虽然音质降低了,但是大部分人普通设备听觉不会有太明显的差别和听觉上的降低,压缩的123K等就是压缩的等级。
1、模型量化的关键结论:
浮点数靠尾数长度决定精度:FP32尾数23位,能精确表示π值的前7位;FP16尾数10位,精度明显下降;BF16尾数仅7位,丢失大量小数细节。
整数必须依赖量化Scale:INT8通过合理Scale可还原小数,但有范围限制;INT4因范围太小(-8~7),几乎无法准确表示小数。
大模型量化常用INT8:在精度和速度间取得平衡,体积比FP32小4倍,通过精心设计的Scale和校正算法,能将误差控制在可接受范围内
2、量化等级:
定义:量化等级是指将连续或高精度的数据(如浮点数)转换为离散或低精度表示(如整数)时所划分的“级别”数量。量化等级决定了数据的表示范围和精度。
3、常见量化等级
8-bit 量化:将32位浮点数(FP32)映射到8位整数(INT8),这是最常用的量化等级。例如,将数值范围[-1.0, 1.0]均匀划分为256个离散值(0-255)。优点:显著减少内存占用(4倍压缩),加快计算速度。缺点:可能引入轻微精度损失。
4-bit 或更低:进一步压缩模型,但需要更复杂的量化策略(如非线性量化、混合精度)。优点:内存占用更小(适合边缘设备)。缺点:精度损失更大,需要精细调整。
二值化(1-bit):将权重或激活值压缩为±1两种取值,极端情况下可将模型压缩32倍。优点:极致轻量化,适合超低功耗设备。缺点:精度损失严重,适用场景有限。
4、量化等级的选择
任务需求:高精度任务(如目标检测)可能需要8-bit,轻量级任务(如语音唤醒)可用更低比特。硬件支持:需匹配目标硬件的计算单元(如GPU/TPU对INT8有优化)。精度与效率权衡:量化等级越低,效率越高,但精度损失风险越大。
- 大模型精度(FP16,FP32,BF16)
浮点数就是小数,比如 3.14、2.718 等。在计算机中,小数不能像整数那样直接表示,因为小数有小数点,而且小数点的位置可以变化(“浮点”就是这个意思)。计算机需要用一种特殊的方式来存储和计算小数。
FP16:小而快,精度低,适合对精度要求不高的场景。
FP32:标准格式,精度高,适合大多数计算。
BF16:介于 FP16 和 FP32 之间,动态范围大,适合特定的机器学习场景。
| 格式 | 结构 | 二进制示例 | 实际存储值 | 误差 | 备注 |
|---|---|---|---|---|---|
| FP32 | 1位符号 + 8位指数 + 23位尾数 | 0 10000000 10010010000111111011010 | 3.1415925414 | ≈0.0000001 | 完整浮点数表示,精度极高 |
| FP16 | 1位符号 + 5位指数 + 10位尾数 | 0 10000 1001001000 | 3.140625 | ≈0.0009676 | 半精度浮点数,尾数减少到10位,精度降低 |
| BF16 | 1位符号 + 8位指数 + 7位尾数 | 0 10000000 1001001 | 3.125 | ≈0.0165926 | 保留FP32的指数范围,但尾数精度大幅降低 |
| INT8 | 8位整数(无符号) | 11001000 (200) | 3.14 (使用Scale=0.0157) | 理想情况下可控制在1%内 | 需通过量化并使用Scale还原,范围有限 |
| INT4 | 4位整数(有符号) | 0011 (3) | 3.426 (使用Scale=1.142) | ≈+8.9% | 极低精度,误差极大,仅适用于粗略表示 |
- SDK和API
SDK的概念:全称为 Software Development Kit,翻译过来的意思就是软件开发工具包。这是一个覆盖面相当广泛的名词,简单来说就是:辅助开发某一类软件的相关文档、演示举例和一些工具的集合,这些都可以称为 SDK。SDK 被开发出来的意义是为了减少开发者的工作量。例如:某公司开发出某种软件的某一功能,将其封装成 SDK(例如数据分析 SDK,就是能够实现数据分析功能的SDK),出售给其他需要的公司使用。这样就可以大大减少开发应用程序的工作量。
API的概念:应用程序接口(全称:Application Programming Interface,简称:API)又称为应用编程接口、应用程序编程接口。提供用户编程时的接口,是一些预先定义的函数,或者软件系统不同部分组成衔接的约定。主要目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。提供API所定义的功能的软件称作此API的实现。API是一种接口,故而是一种抽象。主要功能为提供通用功能集,API同时作为一种中间件,为各平台提供数据共享的能力。
两者的区别:SDK 是一种开发工具包,提供开发所需的资源(库、工具、示例代码等)来帮助开发人员建立应用程序。API 是一种规范和接口,定义了不同应用程序之间的通信方式,允许它们进行数据交换和相互调用。SDK 通常包含 API,但不限于 API,它还提供了其他开发所需的工具和资源。使用 SDK,开发人员可以更方便地使用 API,并利用所提供的功能和特性来构建应用程序。
- Multi-Agent
Multi-Agent System 是指一个系统中有多个智能体同时工作的情况。在这样的系统中,每个智能体都具有一定程度的自主性,可以独立执行任务、做决定,并且能够与其他智能体进行交互,协作完成更复杂的任务或达成共同的目标。
- MCP(模型上下文协议)
模型上下文协议(Model Context Protocol,简称 MCP)是一种开放标准,旨在标准化大型语言模型(LLM)与外部数据源和工具之间的交互方式。由 Anthropic 于 2024 年 11 月推出,MCP 通过定义统一的接口,使 AI 应用能够安全、灵活地访问和操作本地及远程数据资源,提升模型的功能性和可扩展性。
- 计算量和参数量与模型大小关系
在深度学习领域,设计一个模型,需要对模型进行参数量以及计算量的评估。
参数量(Params):用来形容模型的大小程度,类似于算法中的空间复杂度。参数的数量,通常以M为单位。
计算量(FLOPs):用来描述模型的执行效率,类似于算法中的时间复杂度。即每秒的浮点运算次数。
- MoE架构
混合专家模型 (Mixed Expert Models,简称 MoEs) ,最早是随着 Mixtral 8x7B 的推出而逐渐引起人们的广泛关注。最近随着DeepSeek的爆火,MoE又进一步引起大家的关注。
- 裸金属服务器
- 评测指标解析(准确率/精确率/召回率/F1分数/rouge/Perplexity/BLEU)
准确率(Accuracy)是用来评估分类模型性能的一个重要指标。它表示模型正确预测的样本数占总样本数的比例。
精确率(Precision)是一个重要的性能指标,用于衡量分类模型在预测为正类时的准确性。它表示在所有被模型预测为正类的样本中,实际为正类的比例。
召回率(Recall)是一个重要的性能指标,用于衡量分类模型在实际为正类的样本中,预测正确的比例。
F1分数是一个重要的性能指标,用于综合评估分类模型的精确率(Precision)和召回率(Recall)。它特别适用于类别不平衡的数据集,因为它能够平衡这两个指标的影响。
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一种用于评估自动文本摘要和机器翻译质量的指标。它通过比较自动生成的摘要与参考摘要(通常是人工生成的)之间的相似度来进行评估。
Perplexity(困惑度)是自然语言处理(NLP)中一种常用的评估语言模型性能的指标。它衡量了语言模型在预测文本序列时的“困惑”程度,反映了模型对下一个词的预测能力。
BLEU(Bilingual Evaluation Understudy)是一种用于评估机器翻译质量的指标。它通过比较机器翻译输出与一个或多个参考翻译之间的n-gram重叠来进行评分。
详情参考:【大模型】评测指标解析(准确率/精确率/召回率/F1分数/rouge/Perplexity/BLEU) - Syw_文 - 博客园
- 小模型和小模型
小模型通常指参数较少、层数较浅的模型,它们具有轻量级、高效率、易于部署等优点,适用于数据量较小、计算资源有限的场景,例如移动端应用、嵌入式设备、物联网等。
而当模型的训练数据和参数不断扩大,直到达到一定的临界规模后,其表现出了一些未能预测的、更复杂的能力和特性,模型能够从原始训练数据中自动学习并发现新的、更高层次的特征和模式,这种能力被称为“涌现能力”。而具备涌现能力的机器学习模型就被认为是独立意义上的大模型,这也是其和小模型最大意义上的区别。
相比小模型,大模型通常参数较多、层数较深,具有更强的表达能力和更高的准确度,但也需要更多的计算资源和时间来训练和推理,适用于数据量较大、计算资源充足的场景,例如云端计算、高性能计算、人工智能等。
- transformer
Transformer是主流大语言模型的基础架构,但其核心的自注意力机制 (selfattention mechanism) 无法区分词的位置。在自然语言中,词的顺序往往对理解句子的含义至关重要。因此,研究者 常常通过融入位置编码的方式,使 Transformer 能够更好地捕获词的位置信息。这种改进使得模 型在理解语义和处理相关任务时表现更加出色,从而提升了整体的性能表现。基 于Transformer 的预训练语言模型主要通过位置编码来区分文本位置。 Transformer 核心 的自注意力机制本身并不考虑词的顺序,也就是说,它对输入序列的处理是与位置无关的。
- 词元和字符
词元化(Tokenization)是把一段自然语言文本拆分成更小的单元(称为“词元”,即 Token)的过程。词元可以是:
单词:例如,“I love NLP” 分成 ["I", "love", "NLP"]。
子词:例如,“loving” 分成 ["lov", "##ing"]。
字符:例如,“hello” 分成 ["h", "e", "l", "l", "o"]。
这些词元最终会被转换成数字表示(模型的输入),因为机器只能处理数字。
- 模型大小(参数量)和模型性能
大模型的性能很大程度上取决于它们所训练的数据规模和质量。由于各个大模型的词表与所用的分词算法不同,因此我们采用词元数量作为大模型所用数 据量的衡量单位。
表2-1主流开源大模型的预训练数据集词元数量
| 模型名称 | 模型大小(参数量) | 预训练数据集词元数量 |
| PaLM | 5400亿 | 0.78万亿 |
| GPT-3 | 1750亿 | 0.3万亿 |
| Llama | 70亿/130亿 | 1万亿 |
| Llama | 330亿/650亿 | 1.4万亿 |
| Llama 2 | 70亿/130亿/340亿/700亿 | 2万亿 |
| Llama 3 | 80亿/700亿 | 15万亿 |
| Bloom | 1760亿 | 0.34万亿 |
| OPT | 1750亿 | 0.18万亿 |
| MPT-7B | 70亿 | 1万亿 |
| Qwen | 18亿 | 2.2万亿 |
| Qwen | 70亿 | 2.4万亿 |
| Qwen | 140亿 | 3万亿 |
| ChatGLM | 1300亿 | 0.4万亿 |
| Baichuan 1 | 70亿 | 1.2万亿 |
| Baichuan 1 | 130亿 | 1.4万亿 |
| Baichuan 2 | 70亿/130亿 | 2.6万亿 |
| DeepSeek | 70亿/670亿 | 2万亿 |
| DeepSeekMoE | 160亿 | 2万亿 |
| DeepSeek-V2 | 2360亿 | 8.1万亿 |
- 困惑度
困惑度(Perplexity)是一种衡量语言模型预测样本的好坏的指标,常用于自然语言处理中。一种常用的评估语言模型性能的指标。它衡量了语言模型在预测文本序列时的“困惑”程度,反映了模型对下一个词的预测能力。如果一个模型预测得越准确,则其困惑度越低。数据在模型上的困惑度越高,意味 着模型对于这些数据的预测越不确定,从而反映出模型对这些数据的理解和掌握程度较差。这 也可以解释为模型在这些数据上的表现缺乏信心。有人可能会问,现在不是有各种榜单、测试集去测量大模型的能力吗?为什么还需要用困惑度指标?这是个好问题。大语言模型一般分为两种:base模型和chat模型。我们日常通常使用的是对话模型(比如ChatGPT),这种模型具有进行对话的能力,而基础模型则无法直接对问题产生回答。对于这些无法直接生成回答的基础模型来说,困惑度就变成了一种合适的评估指标。相关文章可以参考:深入理解语言模型的困惑度(perplexity) - 知乎
- 数据的质量和多样性
在大模型数据预处理流程中,为了确保数据的多样性和质量,主要应关注两方面: 一是存 量数据的去重,二是增量数据的数据采样。去重和采样的过程是数据清洗的重要前置过程,这 两个过程也可以有机结合起来。数据采样对于数据配比的构造过程具有重要意义,而数据的配比是大模型预训练中非常重要的一个环节,直接影响预训练的效果。在所谓“对齐税”问题。正如在关于ChatGPT 的论文里所提到的,监督微调可能会使模型过拟 合到监督微调的数据上。然而,尽管存在这种过拟合,但一定程度上也有助于获得人类的偏好。 通过监督微调,我们可以更好地调整过拟合和欠拟合之间的平衡,从而提升模型在特定风格或 领域中的性能。当然,这种对齐操作对于大模型的通用基础能力是有损的,这种损失通常被称 为“对齐税”。
- 过拟合和对齐税
在大模型的监督微调阶段,技术流程上涉及在特定的数据上进行微调训练。此阶段所用数 据的质量要求要高于预训练阶段,并且这些微调数据往往需要大量的人工标注和撰写,其消耗 的人力成本相对较高。通过学习这些高质量的对话指令数据,模型可以更好地对齐人类期望的 交互格式、风格和内容,进而确保其输出更加遵循人类的交流习惯。另外,监督微调过程中存
- 扩展法则
扩展法则是大模型训练中观察到的一种现象,其描述了模型的效果与训练数据量、训练计 算量和模型参数量之间的关系。在训练开始之前,研究者可以使用同样结构但是参数量很小的 模型进行快速验证迭代,进而使用实验结论来拟合扩展法则的统计曲线,从而提前预测达到对 应的效果所需的模型大小和数据集规模。扩展法则描述了模型大小、数据集大小和计算资源与模型性能之间的关系。在预训练大模 型时,理解和应用扩展法则可以指导资源的有效分配。扩展法则使研究者能够在不需要进行全量数据的模型训练情况下, 提前确定匹配的数据大小和模型最终表现。因此,在大模型预训练成本非常高的情况下,与扩 展法则相关的实验可以帮忙节省训练资源,减少盲目实验带来的损耗。
- 持续学习、持续预训练
“持续学习”一直是机器学习领域研究的热门话题。特别是在训练成本极高的大模型领域, 如何保持模型已学会的知识,同时更好地学习新技能,更是一个值得讨论的话题。
在进行基座训练时,大模型使用了大量的图书、指令数据等。同样,当模型进入到特定场 景内的持续预训练阶段,以及针对特定问答数据的监督微调阶段时,大模型也需要大量知识密 集型的场景相关数据。因为持续预训练的目的是向模型中注入一些领域相关知识,并且训练时 每个词元都会参与损失的计算,对训练数据的质量要求比较高,所以我们可以使用场景知名的 技术文档、图书等高质量的知识密集型数据作为大模型知识补充的重要手段。
- 基座模型与对话模型
基座模型:通常代表预训练阶段,而聊天模型代表后训练阶 段。诸如Llama 、Baichuan 、Qwen 等众多开源大模型在发布的时候会提供基座模型和聊 天模型。仅经过大量语料进行预训练得到的模型一般称作“基座模型”。在大模型的预训练阶 段,我们通常希望模型能够通过逐个词元的监督学习学到全部的文档信息。为了满足这些要求,通常我们会使用大量知识密集的Wiki文档或网站上的高质量 内容等。预训练使得模型既具备通用的语言能力(针对给定的输入可以进行合理的续写),也 具备对人类自然语言比较好的理解能力。但是,此时的基座模型并没有根据对话数据进行监督 微调,因此并没有很好地适应对话等任务,并且还未学会怎样利用自己的语言知识来回复用户。 这个时候,如果查看模型的生成内容,你会发现模型更倾向于执行针对输入的续写任务,而不 是专门进行对话任务。
对话模型:模型需要通过两个对齐阶段(分别是监督微调阶段和 RLHF 阶段)来适应人类的对话场景,从而得到一个更擅长对话任务的模型,也就是“聊天模 型”。在多轮的指令微调过程中,我们需要为模型加入适当的角色提示词来提示模型当前正处于 对话场景。
- 塌缩
我们经常听到的一种说法是,聊天模型在对比基座能力时有可能出现“塌缩”的现象。在 实践中,算法工程师也经常遇到模型经过监督微调后失去较多通用能力的情况。大模型通用能 力遗忘问题是不可忽视的,这一问题通常被称为“灾难性遗忘”,在深度模型持续学习领域经常 遇到,并且已成为大模型应用中尤其需要关注的问题。大模型的纯解码器架构以及语言模型的 逐词预测任务本身,决定了问题建模的对象仍然是以分类任务的损失函数作为基础来预测下一 个词元。如果在微调阶段直接使用全部的领域内数据,那么模型更倾向于为了拟合微调数据的 分布情况而提升领域内相关说法的生成概率,这样容易导致通用数据训练后的概率空间被破坏, 形成一个有偏的模型。
在理想情况下,可以使用大模型预训练阶段的数据加上领域微调的数据重新训练模型,这 种向大模型注入领域知识的方法对通用能力的影响最小。但是重新训练大模型的计算资源成本 是巨大的,因此很难直接重新训练模型。
- 大模型语义建模的典型架构
大模型的隐含语义是通过构建语言模型来学习的。这一过程涉及向大模型“投喂”大量的 数据以进行训练,从而使得模型本身具备语言模型续写的能力。大模型通过理解语义解答具体的任务问题,可以采用两种典型的方式: 一种是零样本推断; 另一种是少样本推断,或者称为“上下文学习”(in-context learning)。这两种方式都可以通过训练过的语言模型的前向推断,把要回答问题的关键语义信息编码 到最后的隐藏状态 (hidden state) 中。随后,通过自回归的逐步预测的形式依次解码这些隐藏 状态,直至遇到结束符。大模型隐含语义建模的过程,就是通过预训练将其嵌入到语言模型的 参数之中。隐含语义向量的解码过程,就是在推断的时候,根据输入进行前向传播的计算过程。
大模型有如下3种典型的架构。纯编码器 (encoder-only) 架 构、编码器 一 解码器 (encoder-decoder) 架 构 、纯 解 码 器 (decoder-only) 架 构
- 训练的三个阶段
大模型的训练过程可以概括为3个阶段,分别是预训练 (pre-training)、监督微调和偏好 对齐 (preference alignment,也就是人类反馈强化学习);预训练主要是为了有效利用大规模无标签语料进行语义表达的学习,监督微调和强化学习主要解决对齐人类偏好的问题,其顺序和流程不可更改。
预训练:主要是使用真实世界的语 料库为模型注入大量的人类语言知识。通过这种方式得到的模型通常被称为“基座模型”(base model) 。 由于训练任务的设置,此时的模型对于输入更倾向于进行文字的续写,而其训练阶段 的多样化数据本身也导致模型在输出文本时展现出较强的多样性。预训练过程为大模型提供了基本的知识储备和语言模型的泛化能力,从而为监督微调阶段 奠定了坚实的基础。
监督微调:模型训练 需要大量的指令数据作为模型的提示词。这些提示词模拟了用户的对话输入,允许模型通过与 这些模拟输入的交互来学习和适应多轮问答等复杂的对话状态。在这一过程中,指令数据作为 大模型的输入会参与模型的注意力计算。然而,微调的目的是希望模型学到如何针对用户的指 令、提问等,结合预训练时学到的知识,进行合理的回复。通过这种方式,模型被优化为能够 理解和回应特定指令的对话模型 (chat/instruct model)。
强化学习:大模型的强化学习和监督微调的初衷是一致的,即为了更精确地对齐人类的偏好和期望。 但是监督微调和强化学习的设置有所区别。我们可以从这样的流程角度来理解:预训练过程 是给监督微调冷启动,监督微调是给人类反馈强化学习 (Reinforcement Learning from Human Feedback,RLHF) 冷启动。强化学习过程可以通过采样来构造出无限的样本,充分利用监督微调模型和奖励 模型的优势,把构造数据的过程交给模型采样的过程,把判别好坏的过程交给奖励模型。这样, 强化学习就有更强的泛化能力来对齐模型。另外,在这个过程中,有一些地方需要特别注意, 比如对齐的模型和奖励模型的能力需要同步匹配进化,以防止大语言模型自身的基础能力太强 之后,奖励模型丧失对采样样本的质量判断力。虽然奖励模型的建模难度要低于大语言模型, 但是也要时刻关注奖励模型的打分分布是否存在漂移现象。
- 损失掩码和注意力掩码:
损失掩码(Loss Mask)是深度学习中用于选择性过滤无效数据的技术,通过在损失计算阶段屏蔽特定位置的误差贡献,确保模型训练时仅关注有效或有意义的数据。其核心作用是优化模型训练效率,避免无效数据(如填充占位符、噪声标签)对梯度更新的干扰
- 涌现能力
以不同规模的模型在Arithmetic 评测集(来自BIG-Bench, 是一个测试大模型能否正 确完成3位数加减法运算和两位数乘法运算的评测集)上的表现来说明大模型的涌现能力。对 于 GPT-3, 当浮点运算数未达到102²,或者当模型参数量未达到130亿时,模型的表现接近于随 机选择。但当GPT-3 的浮点运算数超过10²²,或者模型参数量超过130亿时,其在评测集上的 准确率开始快速上升。除了GPT-3 模型,作者还对LaMDA 、Gopher 、Chinchilla 以及PaLM 这 4个大模型在8个主流的评测集上进行了验证。结果表明:当大模型的规模超过某个临界点后, 其表现会出现迅速攀升的现象,且这种提升与模型的结构没有明显的关系。这一现象即体现了 作者所定义的大模型涌现能力。
- 模型的规模、浮点运算数 、模型性能
模型训练时的浮点运算数 (Floating Point Operations,FLOPs) 和模 型的参数量两个指标来表示模型的规模。用浮点运算数来衡量模型规模的原因是,浮点运算数 的计算包含了模型的参数量、训练数据量和训练轮数,因此可以综合地表示一个模型的规模。
- 强化学习阶段(RLHF)中的演员模型、参考模型、奖励模型和评论家模型
主要用于监督微调(SFT)之后的人类反馈强化学习(RLHF)阶段,目的是让模型更符合人类偏好。演员模型生成回答 → 奖励模型评分 → 评论家模型辅助优化 → 参考模型约束稳定性。这些模型在RLHF阶段协作:演员生成内容,参考模型保底线,奖励模型打分,评论家辅助优化,共同让大模型更符合人类偏好。
| 模型 | 训练数据 | 训练阶段 | 作用 |
|---|---|---|---|
| 演员模型 | 初始:监督微调(SFT)数据 | RLHF 阶段持续优化 | 生成回答,在RLHF中根据反馈不断调整 |
| 参考模型 | 冻结的SFT模型(不训练) | RLHF 阶段作为基准 | 提供"标准答案",防止演员模型偏离正常表现 |
| 奖励模型 | 人类标注的偏好数据(如选A/B回答更好) | RLHF 前的独立训练阶段 | 学习人类偏好,自动给演员模型的输出打分 |
| 评论家模型 | 同奖励模型或强化学习环境反馈 | RLHF 阶段与演员模型同步训练 | 预估生成内容的质量,辅助策略优化(如PPO算法) |
- 并行训练:数据并行和模型并行
大模型并行训练的策略主要包含两大类——数据并行和模型并行,其中模型并行又进一步 细分为张量并行和流水线并行。现在,大模型在实际的预训练和 SFT 过程中会使用多种模型并 行方法来优化显存使用。同时,通过混合多维度的训练策略,通信时间消耗得以显著降低。这 些技术使得在由大量高速计算设备组成的集群上进行高效模型训练成为可能。
数据并行:每个设备负责处理不同的数据批次,各自独立地计算梯度后再进行 更新。
模型并行:模型并行通过将大模型按矩阵分块计算(张量并行)或按层切分(流水线并行)的方式分 布到多个设备上,从而达到节省显存的目的。在这种情况下,每个设备中保存的是模型的某一 部分,并在参数更新时独立更新自身负责的子网络。
- 强化学习
强化学习(Reinforcement Learning, RL)是机器学习的一个重要分支,其目标是通过智能体与环境的交互,学习最优策略以最大化累积奖励。在大模型(如LLM)中,强化学习方法被广泛应用于优化模型性能,尤其是在结合人类反馈的强化学习(RLHF)中。
强化学习的核心概念:强化学习的核心包括状态(State)、动作(Action)、奖励(Reward)和策略(Policy)。
在大模型强化学习对齐阶段,通常会选用经过监督微调后具备较好指令跟随能力的大模型来精准对齐人类偏好。目前主流的方法有两种: 一种是在线强化学习(如PPO), 另一种是离线 强化学习(如DPO)。 在在线强化学习中,演员模型在学习时需要不断地与环境进行交互。在 离线强化学习中,策略模型则是直接从偏好数据集中学习。无论是在线强化学习还是离线强化 学习,在实际应用中都面临着各种挑战。例如, PPO 算法由于需要同时训练演员模型和评论家 模型,导致计算开销过大;演员模型和评论家模型之间的相互依赖性导致训练不稳定的问题; 许多高级方法引入了额外的超参数,使得它们在大规模应用中的扩展变得过于复杂
强化学习的几种方式:ReMax 、RLOO 、GRPO以及REINFORCE++;三种标注方式:点对点式、列表式、对偶然式
工作流与智能体Agent
简单地说,代理系统agent包含workflow工作流(自己决定处理路径)以及智能体agent(大模型决定处理路径):
智能体 = 提示词定义角色行为 + 大模型提供推理能力 + 知识库补充专业信息 + 记忆系统维持上下文连续性
工作流(Workflow):面向任务执行,"输入→处理→输出"的线性自动化流程
实际交互关系:双向嵌套关键,区别在于谁拥有“决策权”
1、工作流中包含智能体(常见):将智能体作为工作流中的一个动态决策节点
2、智能体内部调用工作流(新兴趋势)
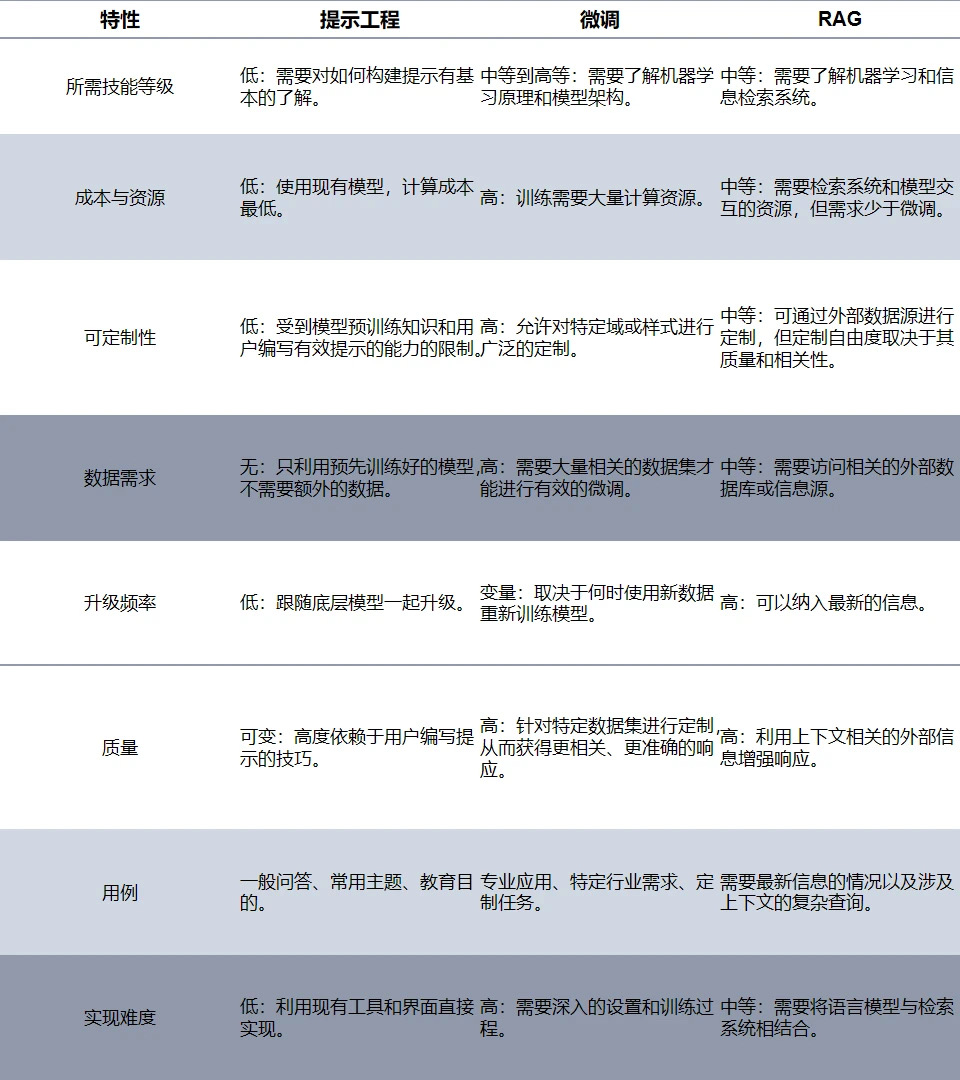
提示词工程和微调、RAG、知识库、enbedding
是否修改了模型的参数,是提示工程和微调的根本区别,一文读懂Embedding嵌入模型的概念:https://zhuanlan.zhihu.com/p/164502624
一些关键知识的学习
数据集:
1、定义:特征、标签、元数据和样本——鹃尾花数据集为样本,长度、宽度等为特征,尾巴羽毛等为标签,时间地点来源等本身信息为元数据2、分类:从流程阶段来看,可以分为预训练数据集、指令微调数据集和评测数据集;从数据应用来看,可以分为通识数据集、行业通识数据集和行业专识数据集
3、数据集评估:静态评估和动态评估
微调方法
常见的几种微调方式:监督微调,包括指令微调、对话微调、领域适配、文本分类、推理能力微调、强化学习、多模态微调、知识蒸馏、全参数微调(Full Fine‑Tuning)、层冻结微调(Layer Freezing)、适配器(Adapter‑Based Tuning)、低秩适配(LoRA, Low‑Rank Adaptation)、前缀微调(Prefix‑Tuning)等等。
微调常用的数据集分为:训练集、验证集、测试集
微调过程关键超参数
- 训练轮数:少则不熟、多则过拟合
- 学习率:决定参数调整幅度,大则快但容易走偏,小则稳定但慢
- 批量大小:每次更新样本数,大则快而粗
所以 ,影响推理性能的关键因素?
1. GPU显存大小:决定了能够加载并运行多大量&精度的模型;
2. GPU算力大小:与首token延时相关 ,算力越高首Token越快;
3. GPU带宽大小:与每token延时有关 ,带宽越大token并发越高;
4. 模型参数&精度:模型参数越大 ,准确率越高 ,逻辑能力越强;
不同模型规模推荐配置
| 模型 | GPU云主机 | GPU裸金属 | |||||||||
| T4 | V100 | V100S | A10 | A100 | L20 | H800 | A800 | L40S | H20 | 昇腾910B | |
| Qwen/QwQ-32B Q4_K_M | pi2.4xlarge.4显存:2*16G | p2v.2xlarge.4显存:1*32G | p2vs.2xlarge.4显存:1*32G | pi7.4xlarge.4显存:1*24G | p8a.6xlarge.4显存:1*40G | pn8i.4xlarge.8 显存:1*48G | 1台physical.h8ns.6xlarge28显存:8*80G | 1台显存:8*80G | 1台physical.h6ns.2xlarge11显存:8*48G | 1台显存:8*96G | 1台physical.acas910b.2xlarge11或physical.lcas910b.2xlarge11显存:8*64G |
| Qwen/QwQ-32B | - | p2v.8xlarge.4显存:4*32G | p2vs.8xlarge.4显存:4*32G | pi7.16xlarge.4显存:4*24G | p8a.24xlarge.4显存:4*40G | pn8i.8xlarge.8 显存:2*48G | |||||
| DeepSeek-R1-1.5B | pi2.2xlarge.4显存:1*16G | p2v.2xlarge.4显存:1*32G | p2vs.2xlarge.4显存:1*32G | pi7.4xlarge.4显存:1*24G | p8a.6xlarge.4显存:1*40G | pn8i.4xlarge.8 显存:1*48G | |||||
| DeepSeek-R1-7B | pi2.4xlarge.4显存:2*16G | p2v.2xlarge.4显存:1*32G | p2vs.2xlarge.4显存:1*32G | pi7.4xlarge.4显存:1*24G | p8a.6xlarge.4显存:1*40G | pn8i.4xlarge.8 显存:1*48G | |||||
| DeepSeek-R1-8B | pi2.4xlarge.4显存:2*16G | p2v.2xlarge.4显存:1*32G | p2vs.2xlarge.4显存:1*32G | pi7.4xlarge.4显存:1*24G | p8a.6xlarge.4显存:1*40G | pn8i.4xlarge.8 显存:1*48G | |||||
| DeepSeek-R1-14B | pi2.8xlarge.4显存:4*16G | p2v.4xlarge.4显存:2*32G | p2vs.4xlarge.4显存:2*32G | pi7.8xlarge.4显存:2*24G | p8a.12xlarge.4显存:2*40G | pn8i.4xlarge.8 显存:1*48G | |||||
| DeepSeek-R1-32B | - | p2v.8xlarge.4显存:4*32G | p2vs.8xlarge.4显存:4*32G | pi7.16xlarge.4显存:4*24G | p8a.24xlarge.4显存:4*40G | pn8i.8xlarge.8 显存:2*48G | |||||
| DeepSeek-R1-70B | - | - | - | - | p8a.24xlarge.4显存:4*40G | pn8i.16xlarge.8 显存:4*48G | |||||
| Qwen-72B | - | - | - | - | p8a.24xlarge.4显存:4*40G | pn8i.16xlarge.8 显存:4*48G | |||||
| DeepSeek-R1&V3满血版(671B)W8A8量化权重 | - | - | - | - | - | - | - | - | - | - | 2台physical.acas910b.2xlarge11或physical.lcas910b.2xlarge11显存:8*64G |
| DeepSeek-R1&V3满血版(671B) | - | - | - | - | - | - | 4台physical.h8ns.6xlarge28显存:8*80G | 4台显存:8*80G | 4台physical.h6ns.2xlarge11显存:8*48G | 2台显存:8*96G | 4台physical.acas910b.2xlarge11或physical.lcas910b.2xlarge11显存:8*64G |
模型参数的量级单位
在使用大模型时,经常看到多少B或者多少M的模型,或者是他的上下文长度为多少K,下面就是对这些常见单位量级的理解:
K(Kilo, 千):表示 1,000。在机器学习模型中,通常用来描述较小模型的参数量,比如 100K(十万)参数。
M(Million, 百万):表示 1,000,000。一般用于中等规模的模型,比如 BERT-base(110M)。
B(Billion, 十亿):表示 1,000,000,000。大型模型通常达到这一量级,比如 GPT-3(175B)。
T(Trillion, 万亿):表示 1,000,000,000,000。这代表非常巨大的参数量。GPT-4
的一些版本和其他超大规模模型已经达到甚至超过 1T 参数。
裸金属服务器
“裸金属”,意味它不包括相应的操作系统和软件,这个是客户后期自选配置的。大部分云服务提供商的裸金属服务器产品,不提供本地硬盘(可以支持),主要提供CPU和内存。







