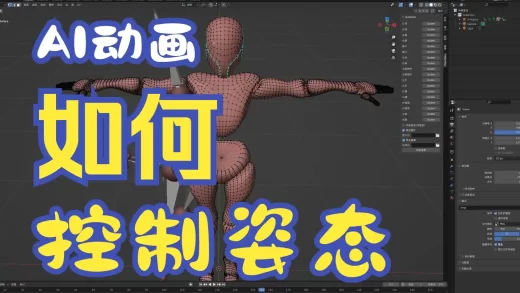
3月份OpenAI发布4o,在理解和执行复杂图像指令上有了颠覆性的进步,一句话P图成了最吸引眼球的功能,但经过测试仍有很多不足之处,比如无法保持原图一致性
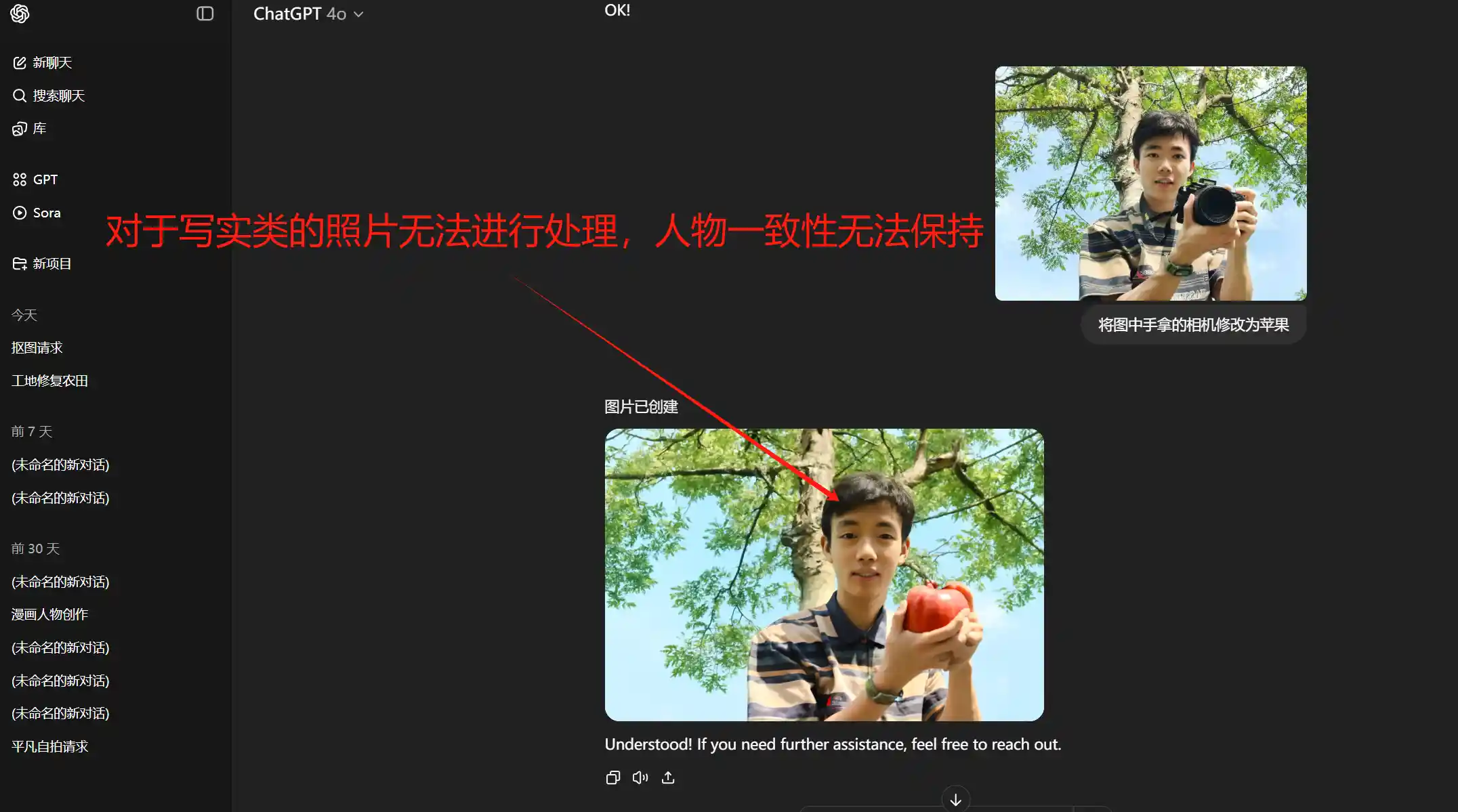
而最近黑森林(原Stability AI的Stable Diffusion核心团队独立出来的公司)推出的FLUX.1 Kontext一上线,真正实现了P图只用嘴,独创的流匹配架构(Flow Matching),让Kontext实现了像素级语义理解,通过简单指令就可以完成复杂图像精准P图,一致性修图难题得到解决。
现在使用Kontext甚至能实现溶图,那么对于中英文文字的处理如何我们将在文章后面进行展开
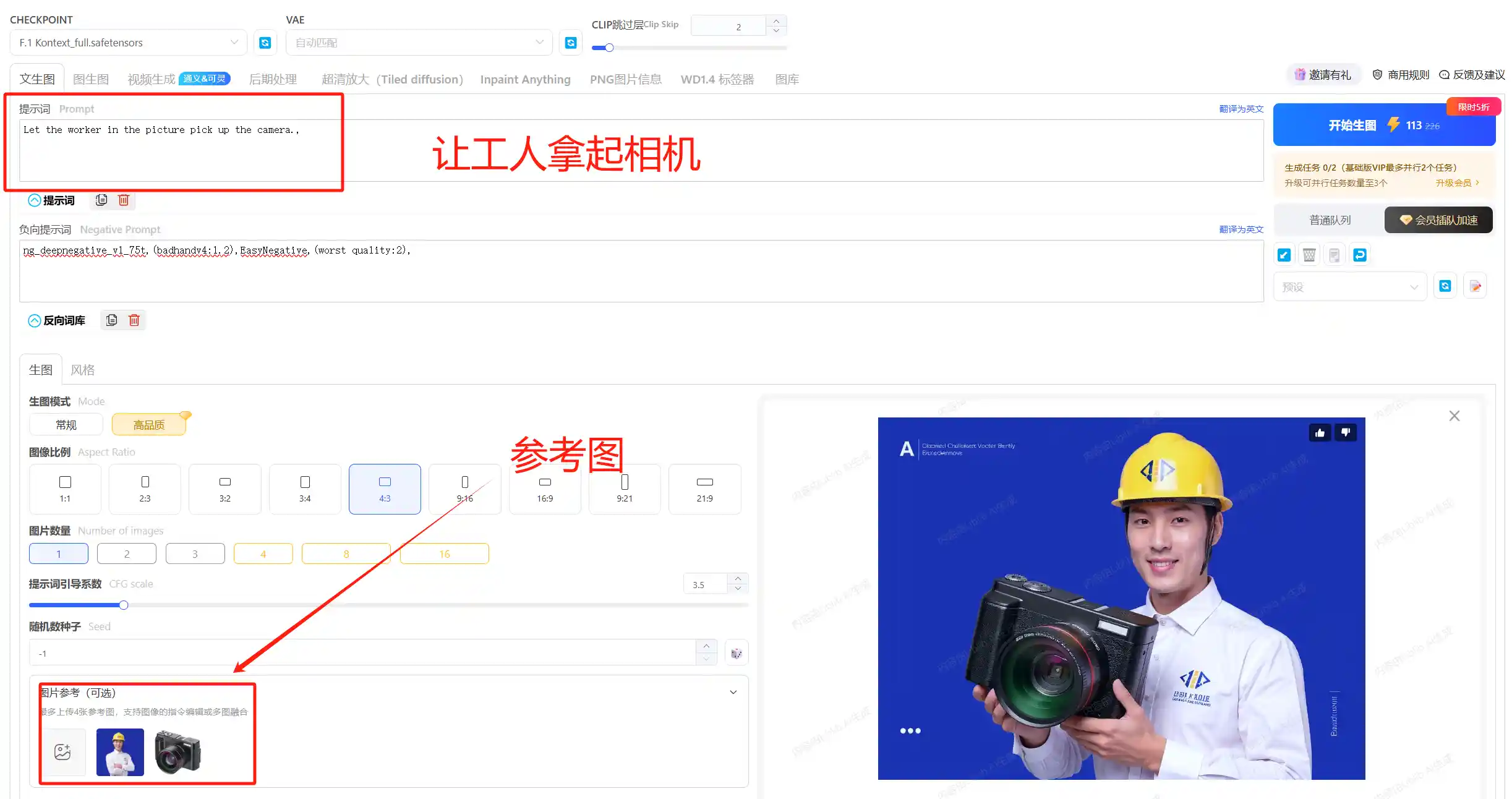
直接让其改变人物中头向,并且让人物微笑,我们可以人物的特征基本保持不变

AI生图发展到现在,已经在各领域全面开花。AI生图技术已进入产业级应用阶段,非专业用户停留在娱乐化尝试阶段(数据来源:2024AIGC消费行为报告),三分钟热度满足好奇心并未真正赋能办公,他们大多会反馈几种情况:
- 缺乏实用场景: 感觉AI生图对实际工作生活帮助不大,找不到应用点。
- 工具两极分化: 简单工具效果差不想用,专业工具门槛高不爱学。
- 真实感不足: 除了二次元,生成的写实图片“一眼假”,无法落地。
- 设计协作困难: 输出无图层、难修改、不支持中文字体生成、无法直接出成品海报。
- 控制精度不够: 无法精准修图(P图),局部修改困难。
- 风格难以稳定: 无法稳定复现特定画风或角色形象,一致性差。
- 设备/成本门槛: 本地部署专业工具需要高性能显卡,云端服务可能持续收费。
那么针对以上问题,选对大模型和工具是关键,基于目前AI生图的的几大主流大模型和应用分别是:
Stable Diffusion、ComfyUI、Midjourney、DALL·E | OpenAI、seedream 3.0、可图
针对以上问题,我们只需要针对这六款工具进行分析即可知道什么时候选择那款工具能实现最好的效果
1、Midjourney:艺术性、视觉冲击力、画面质感更加真实、局部重绘;缺陷:只能用提示词、语义理解较弱、难以控图、中文生成差,必须付费
2、Stable Diffusion:生成逼真程度取决于模型和提示词质量、Lora微调、可控性强、丰富扩展插件、支持开源本地部署;本地部署消耗显卡要求配置高,建议使用:三方平台/云盘/云电脑
3、Comfyui:优势:高效模块化设计,允许用户根据需求自由组合和扩展模块,适合商业批量出图
对显存要求低,启动与运行速度快,流程模板多,生成自由度高;缺点:入门门槛高,流程节点多
4、DELL·e/GPT 4o:优势:语义理解、自然对话、支持中文文字生成但质量一般;缺点:图像质量一般,无法保证人物一致性
5、Seedream 3.0:目前在中文文字生成领域上遥遥领先、成像质量好、自带万物分割、局部重绘、逐层构建、图形参考等功能
6、可图:还行
一、Midjourney新手入门基本技巧掌握
(1)基本前置指令
/imagineCreate images with Midjourney.【出图指令,生成图像】
/describeWrites a prompt based on your image.【图生文】
/shortenAnalyzes and shortens a prompt.【分析关键词】
/blendBlend images together seamlessly!【混合两个以上的图片(最多五张)】
/settingsView and adjust your personal settings.【查看和调整个人设置】
/Info【该平台上的当前状态快照】
/Subscribe【主要用于管理和购买 Midjourney 的订阅服务】
/blend【融合图片】(2)菜单栏指令:
① U1 U2 U3 U4 按钮放大第几张图片
② V1 V2 V3 V4 变换当前按钮第几张图片
③ 🔁 按钮 重新生成
④🔍Upscale按钮将图片放大两倍•【Subtle与原图非常相似】•【Creative与原图有明显的不同】
⑤ 🪄Vary Subtle 变体弱【生成四张图跟原图内容差不多一致,只是改变了一些细节】
⑥🪄Vary Strong 变体强【生成四张图比原图变化更大,无论是衣服、外貌和动作都有更大的不同】
⑦ 🖌️Vary Region 局部重绘【对图像的选定区域进行更改,包括删除不需要的对象或填充缺失的部分】⑧ 🔍Zoom Out 1.5 改变相机视角侧面的细节增强 1.5 倍
⑨ 🔍Zoom Out 2 改变相机视角侧面的细节增强 2 倍
⑩ 平移功能:通过在输入框中点击“⬆️⬇️⬅️➡️”来控制“平移”图片(3)进阶参数表:Midjourney绘画参数和提示词学习与总结 – Jay宇宙
(4)提示词语法:
--no【表示画面中不想出现这个物体】
::【权重提示,例如red::2 white hair则为加重红色,::0.5=--no(他们权重相等)】
--iw【图像权重,和参考图像的相似程度】
--stylize+数字【加重风格化(0-1000)】
panels【连续变化,例如“4 panels with different expression ”,就可以生成4个不同的系列表情】
--raw【写实类】
Chaos命令【让图片发散命令,--chaos+数值(0-100),后面数字越大,生成的图跟描述差异也越大】
链接+提示词【命令框选择/imagine prompt,粘贴链接后写提示词可以参考该图像】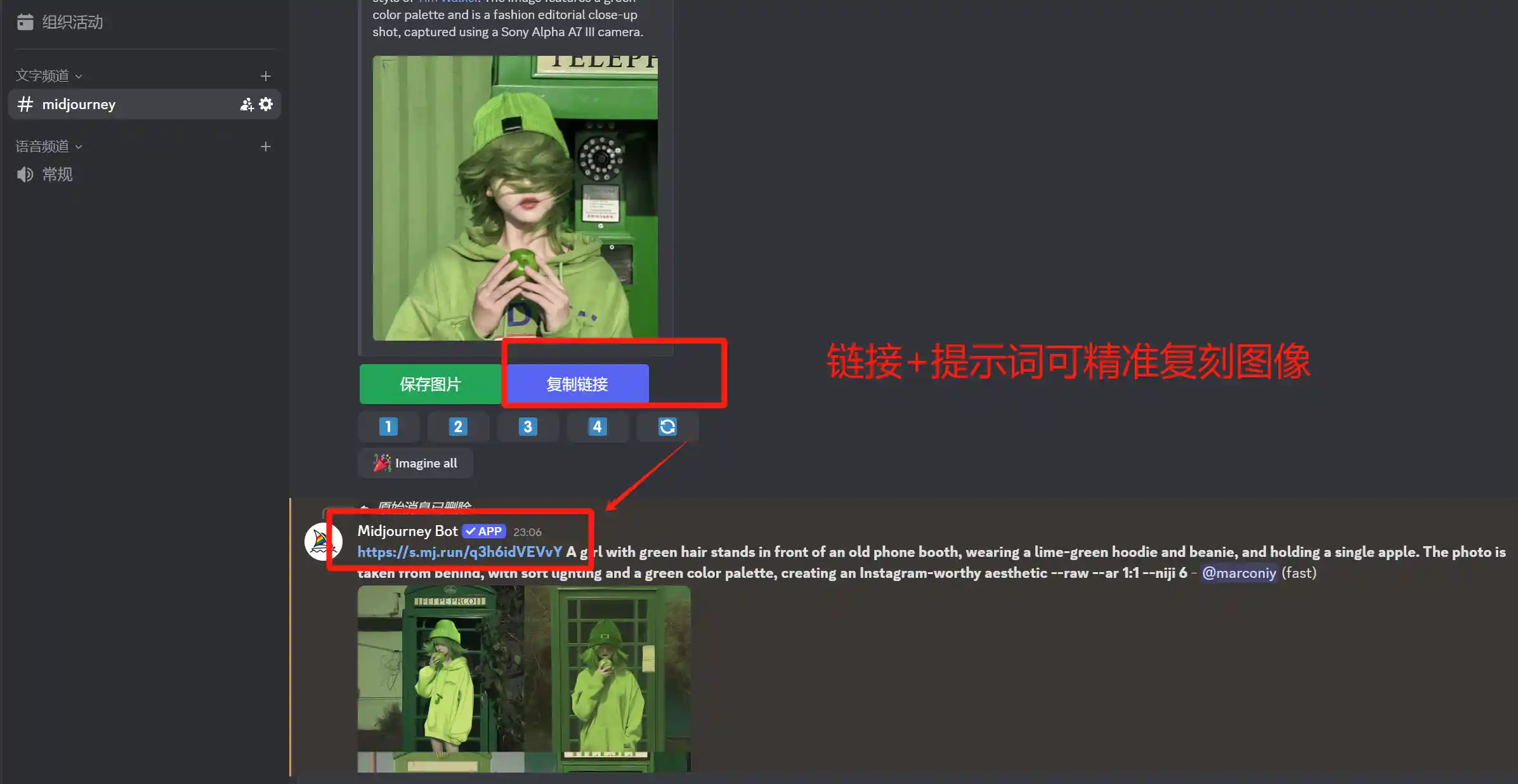
快速绘制一张写实照片(MJ的突出优势就是真实质感)
【其他前置语法:链接/blend/4 panels with different expression/】Wearing blue headphones,Bright sunshine,backlight shooting,large aperture,smile:2,Dancing hair covers the face,romantic use of light,kpop hair color hairstyle in style,kpop hair color with short hair,in the style of green academia,surrealism,instax,experimental photo,light pink blue::2 hair,green grassland,The wind messed up her short hair,graceful movements,dreamlike imagery,naturalist aesthetic,rinko kawauchi style:2 --v 6.0 --raw --ar 3:2 【其他后置语法:--no --iw --s --seed】以上内容比较多,你可以按照以下思路绘制一张图来保证你已经入门:上传一张图,用MJ拆解提示词,接着复制图片链接结合拆解的提示词进行复刻(同时用–iw修改相似度),接着根据图片依次进行修改权重和消除物体(用–no或者::以及局部重绘)、创意风格化(–s)、用4 panels with different expression绘制四个不同角度图片、用种子复刻更多类似的角色(–seed)
(5)角色和风格样一致性
- 角色一致性: 保持图像角色的一致性。 根据你提供的现有角色图像的URL, 生成与之相似的角色。使用方法: 在提示后添加
--cref,并紧接着指向人物参考图像的 URL。示例:/提示词 --cref 链接–cw(0-100) - 风格一致性: 生成类似风格的图片,保持画风的一致性。使用方法: 在提示后添加
--sref,并紧接着指向风格参考图像的 URL。 可以添加多个网址。示例:/提示词 --sref 链接 --sw(0-1000)
二、Stable Diffusion插件Controlnet
为什么建议大家去学,Controlnet是SD发展中革命性的变革,图像从抽卡时代正式迈入可控,借助Controlnet你可以完全控制人物肢体动作、建筑结构等,将极大推动图像生成转变为生产力
文生图效果,提示词,随便复制的无参考价值
(sfw:1.2), absurdres, 1girl, looking_at_viewer, long hair, happy, cheer, surprised, open mouth, big mouth, best quality, masterpiece, (photorealistic:1.4), hands up, high five, fingers,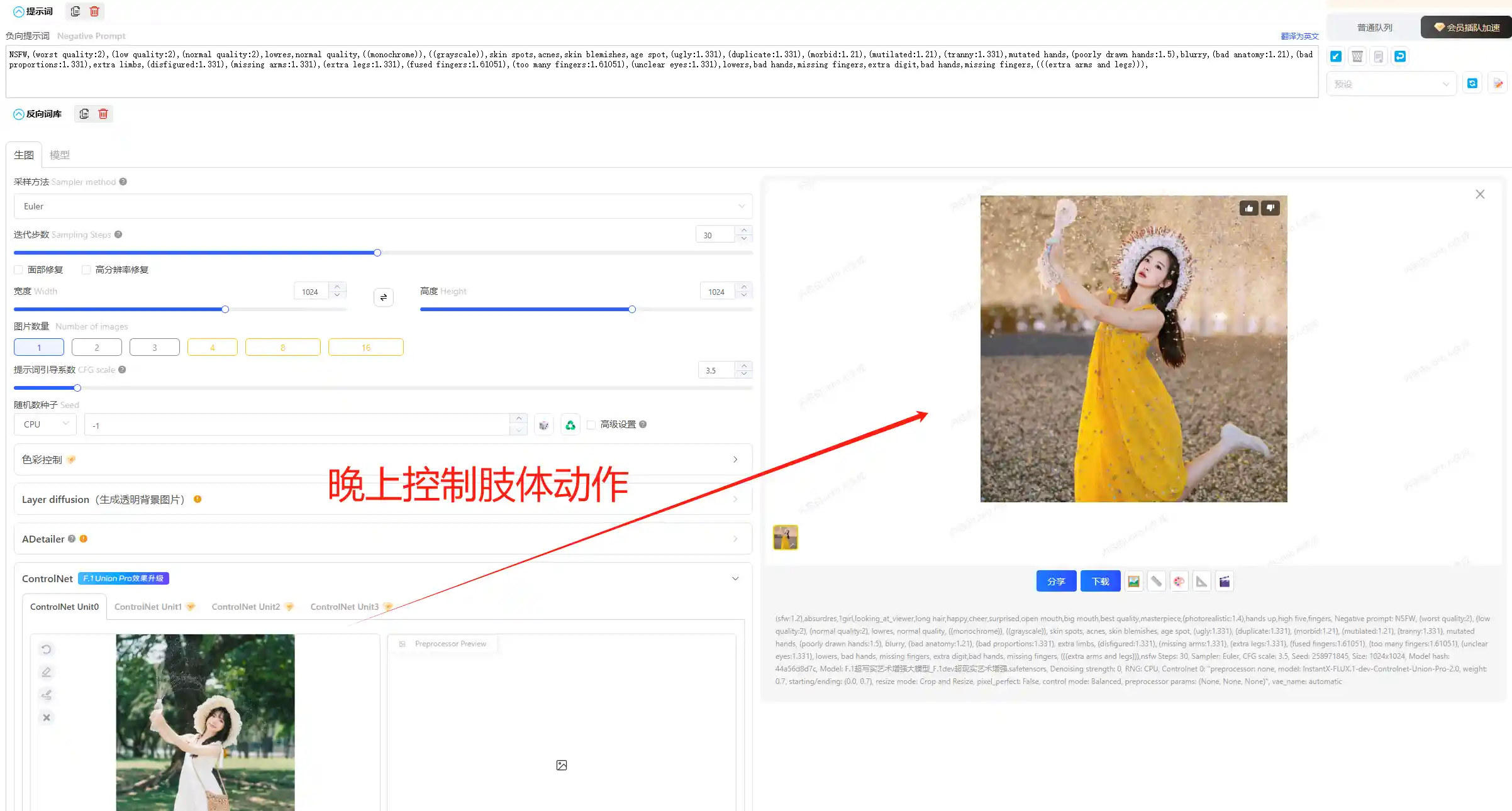
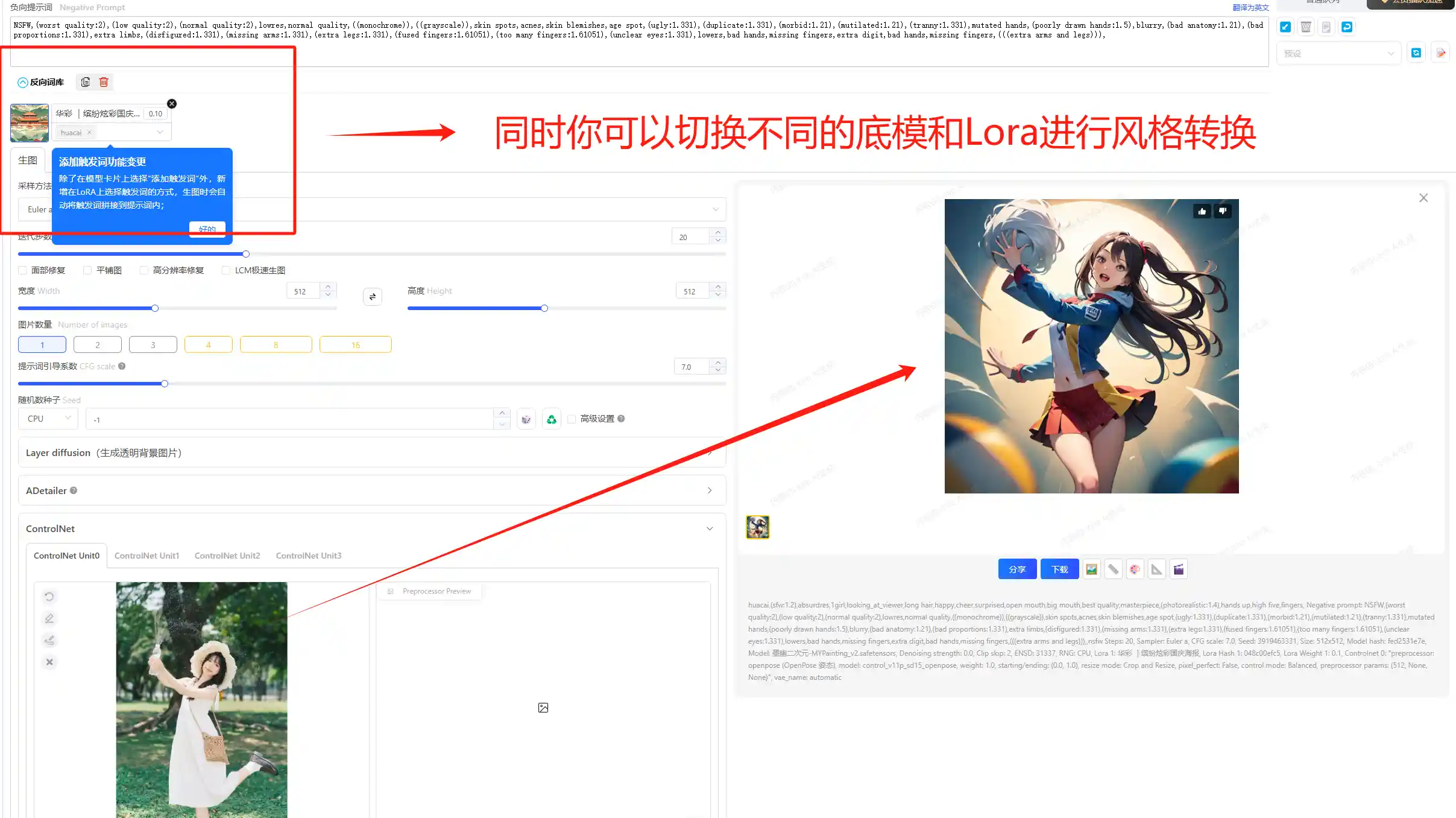
与此同时你可以切换底模和Lora进行风格转换
(1)提示词语法(入门SD,语法先行)
一些基本语法:Stable Diffusion必备的提示词语法指南
常用的一些负面提示词
负面提示词后请添加:
NSFW, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs)))
译:NSFW,(最差质量:2),(低质量:2),(正常质量:2),低分辨率,正常质量,((单色)),((灰度)),皮肤斑点,痤疮,皮肤瑕疵,老年斑 ,(丑陋:1.331),(重复:1.331),(病态:1.21),(残缺:1.21),(变性:1.331),变异的手,(画得不好的手:1.5),模糊,(不良解剖学:1.21) , (比例不良:1.331), 额外四肢, (毁容:1.331), (缺胳)常用的一些正向提示词
(masterpiece:1,2), best quality, masterpiece, hires, original, extremely detailed wallpaper, perfect lighting,(extremely detailed CG:1.2),
译:(杰作:1,2),最佳质量,杰作,雇佣,原创,极其详细的壁纸,完美的照明,(极其详细的CG:1.2)(2)插件资源下载
## ControlNet扩展与模型下载地址
扩展地址:
https://github.com/Mikubill/sd-webui-controlnet
https://github.com/Mikubill/sd-webui-controlnet
1.1版本模型地址:
(下载地址)https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
(模型介绍)https://github.com/lllyasviel/ControlNet-v1-1-nightly
1.14版本后更新的新模型(包括社区模型)与XL模型的地址:https://huggingface.co/lllyasviel/sd_control_collection/tree/main(3)四个基本选项
启动:控制整个插件的开关,必须先开启才能使用
低显存模式:电脑配置低勾选降低压力,但是会降低生成速度为代价
完美像素:建议勾选,会自动计算预处理产生图像适配的图形尺寸,避免尺寸不匹配导致图像变形
预览:字如其名
(3)插件的参数详解
整个插件光是预处理器就要接近40种类,并不建议大家去死记住或者全部掌握,优先掌握通用处理器即可


@B站阿撒

@B站nenly大佬
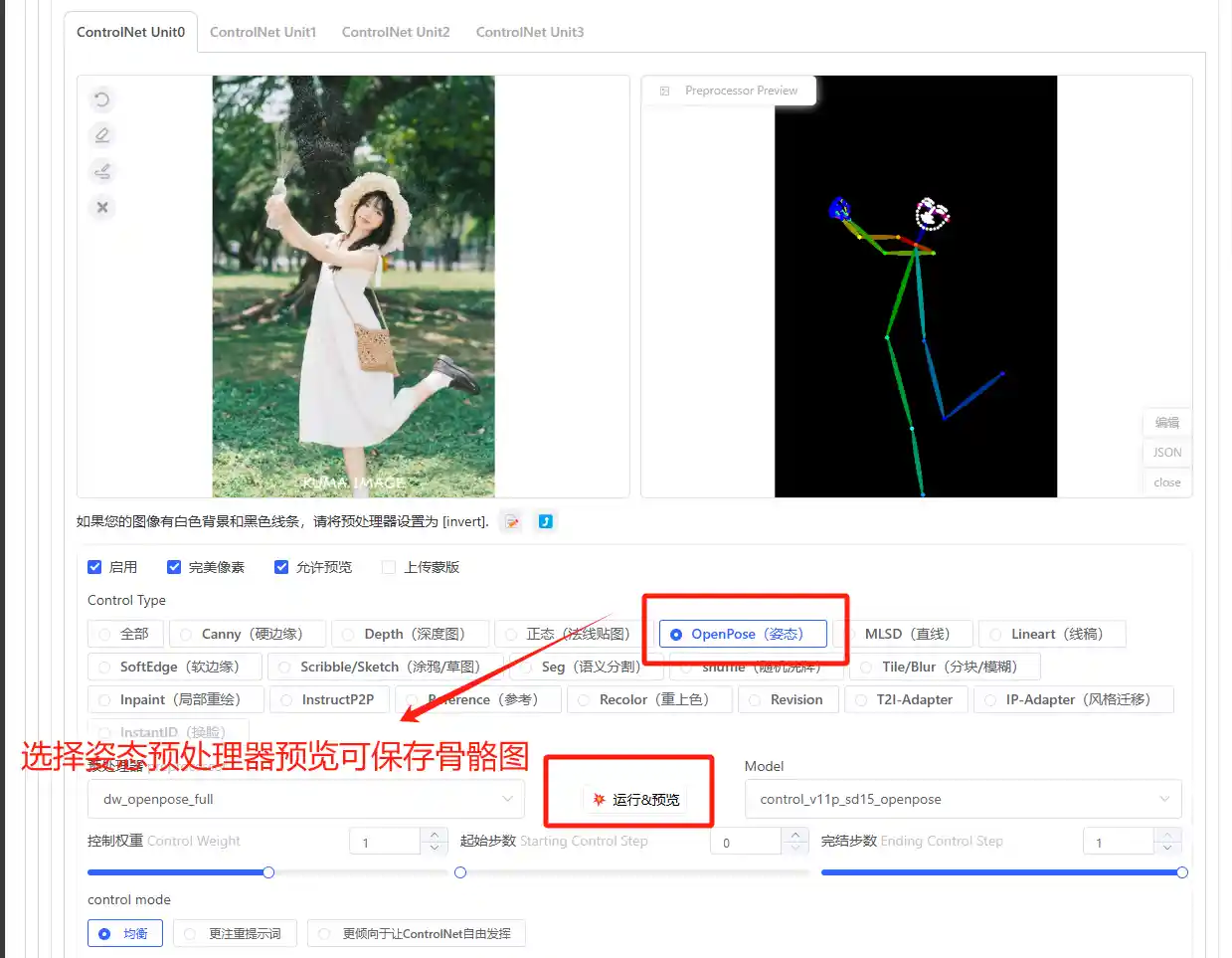
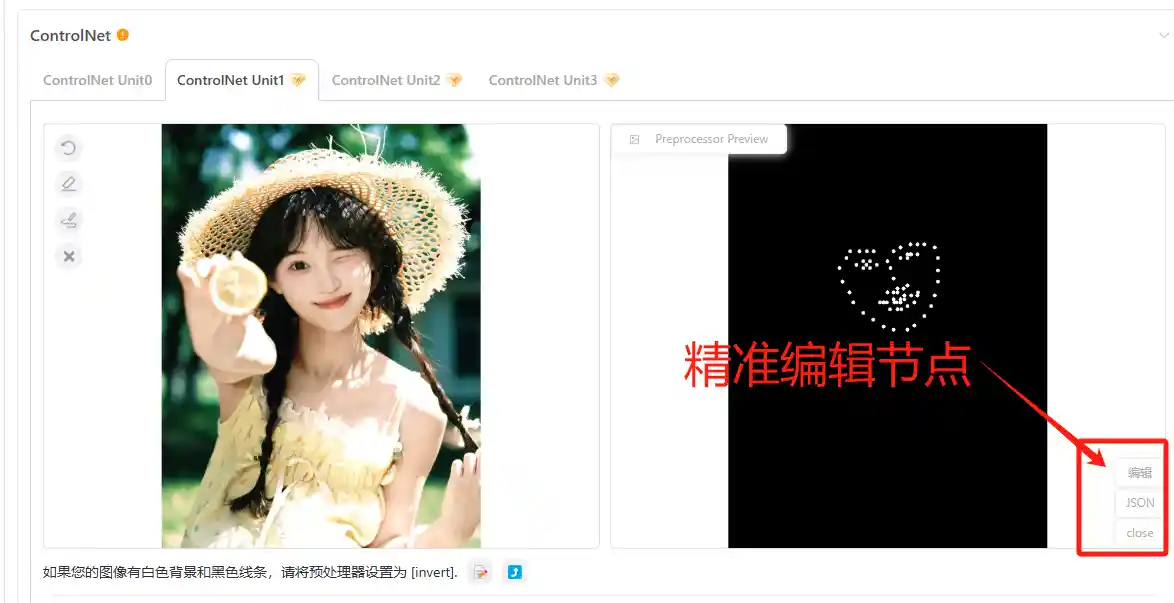
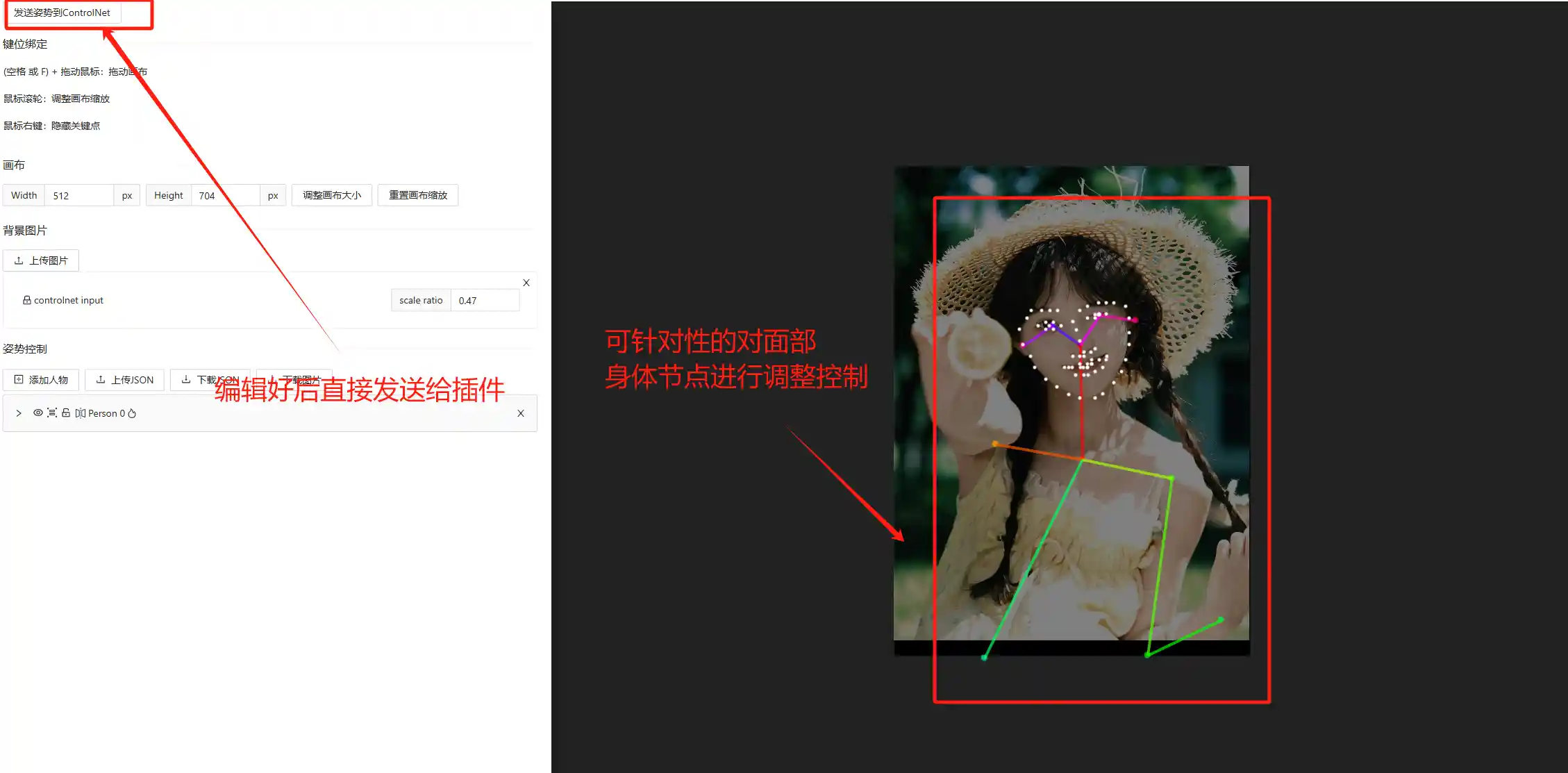
那么除了针对人物动作进行精准控制,我们是否还能精准控制人物表情等其他细部结构呢,当然可以。在预处理器中运行出骨骼图后直接选择编辑即可
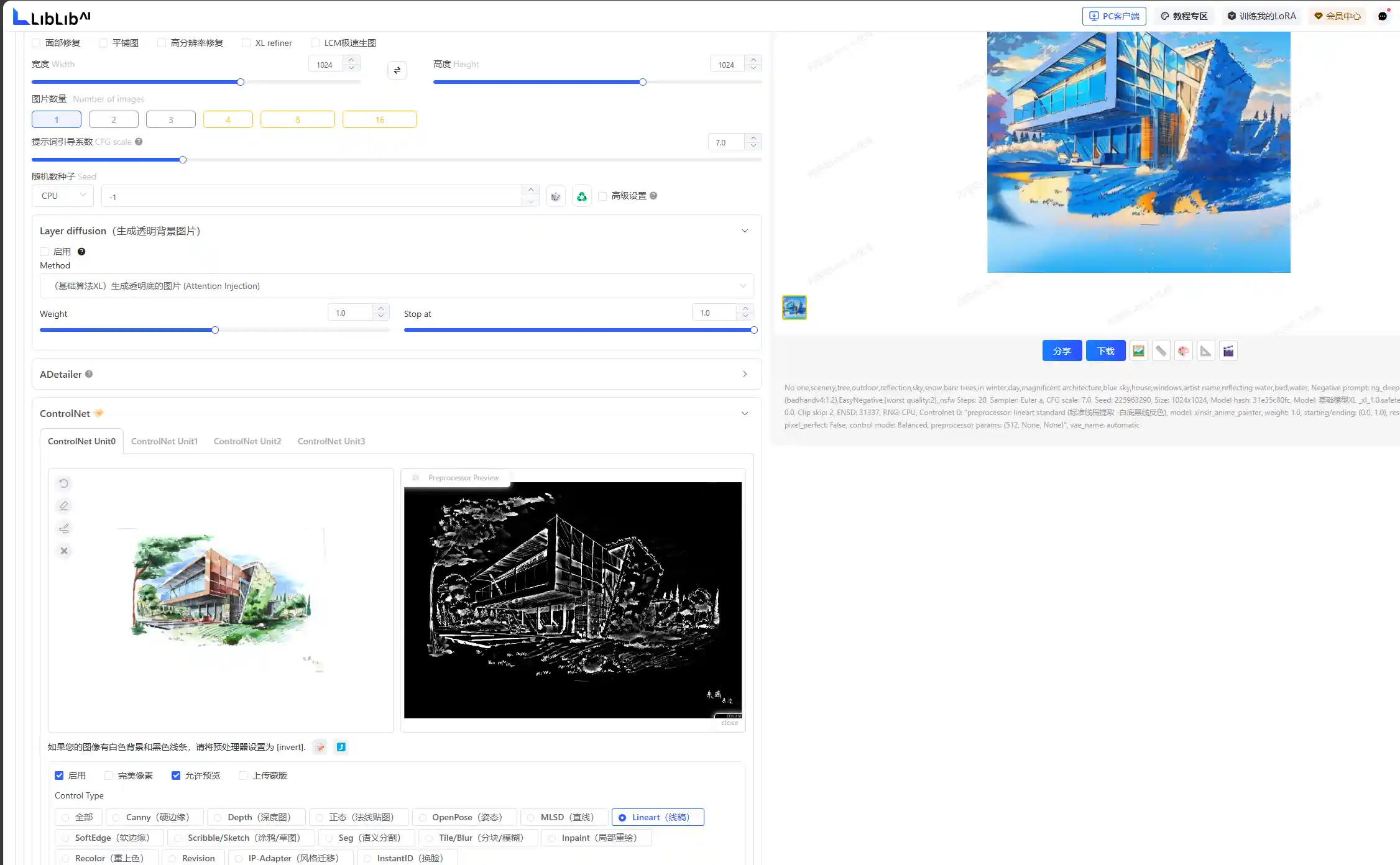
此外,不同的处理器可以进行不同类型图片处理,在工程领域可以选择硬边缘、线稿、柔边缘、草图
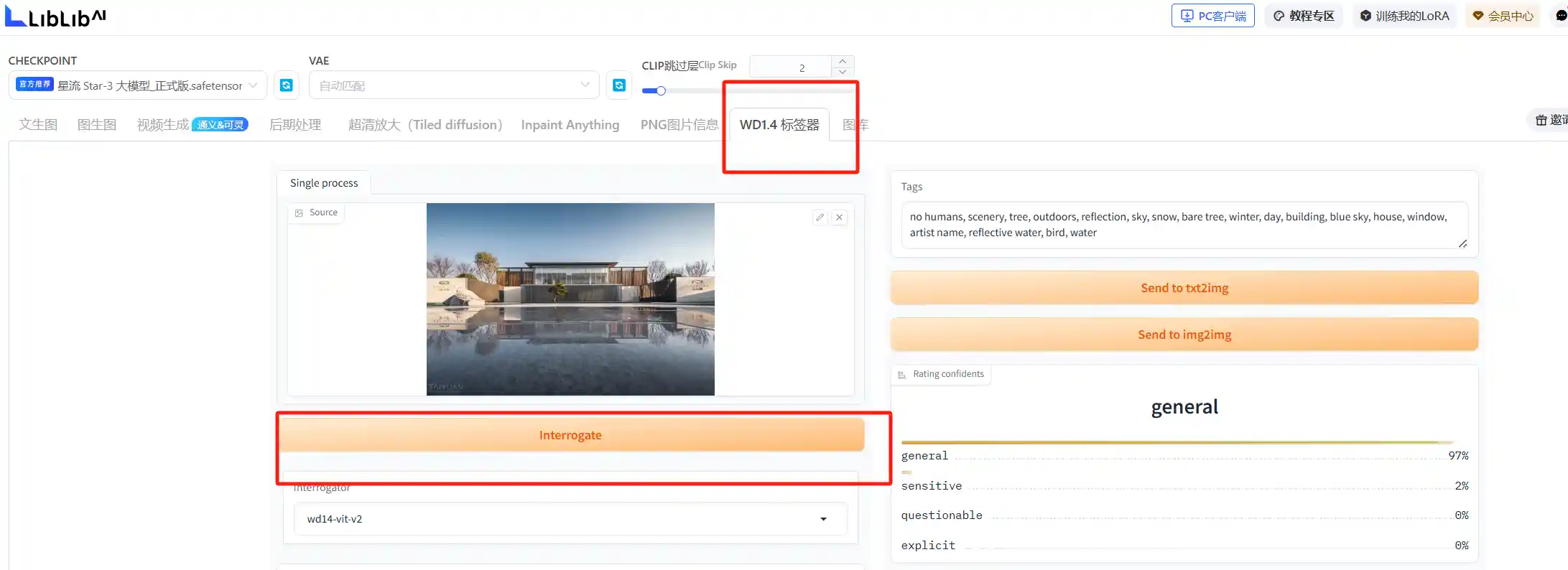
不会写提示词,推荐使用SD的WD1.4标签器,WD1.4标签器是一款专为Stable Difusion设计的插件,用于分析上传的图片并提取出其背后的提示词。
三、即梦3.0(万物分割+中文生成)
四、ComfyUI工作流应用
ComfyUI是目前真正能实现生产力的工具,基于 Stable Diffusion 的 节点式(Node-Based)界面,允许用户使用 拖拽组件 的方式,构建复杂的 A! 生成流程。与 WebUl 相比,ComfyUI采用了更底层的工作流方式,使用户能够精准控制 生成过程中的每一个细节,具有更高的自由度
| 特性 | ComfyUI | Stable Diffusion WebUI |
|---|---|---|
| 操作方式 | 拖拽节点 | 表单式界面 |
| 控制能力 | 极高 | 受限于插件支持 |
| 适合人群 | 高级用户、开发者 | 普通用户 |
| 扩展性 | 极高 | 依赖插件 |
| 性能优化 | 更高效 | 可能更耗资源 |
看起来很复杂,其实也不简单,不过我们可以先从一张图来了解一下他的工作原理