
在日常工作和学习中,我们经常遇到需要将PDF、图片或其他格式文档中的文字提取出来的情况。传统的OCR工具往往对付复杂布局束手无策,特别是遇到表格、图表或多栏排版时,提取效果难以令人满意。
今天介绍的这款名为Zerox的开源工具,利用AI技术实现了零样本OCR识别,能够精准解析复杂布局文档,并输出整洁的Markdown格式,极大地提升了文档数字化的效率和质量。

1. 什么是Zerox?
Zerox是一款基于GPT-4o-mini模型的开源OCR工具,它采用零样本学习(Zero-Shot Learning)技术,无需预先训练就能直接处理各种类型的文档。它将文档转换为图像后利用多模态模型进行识别,最终输出结构化的Markdown格式结果,支持PDF、DOCX、图片等20多种文件格式。
Zerox的核心优势在于能够理解和解析文档的视觉布局和语义结构,而不仅仅是提取文字。它能够识别表格、图表、多栏排版等复杂元素,并保持原有的逻辑关系,这是传统OCR工具难以实现的能力。
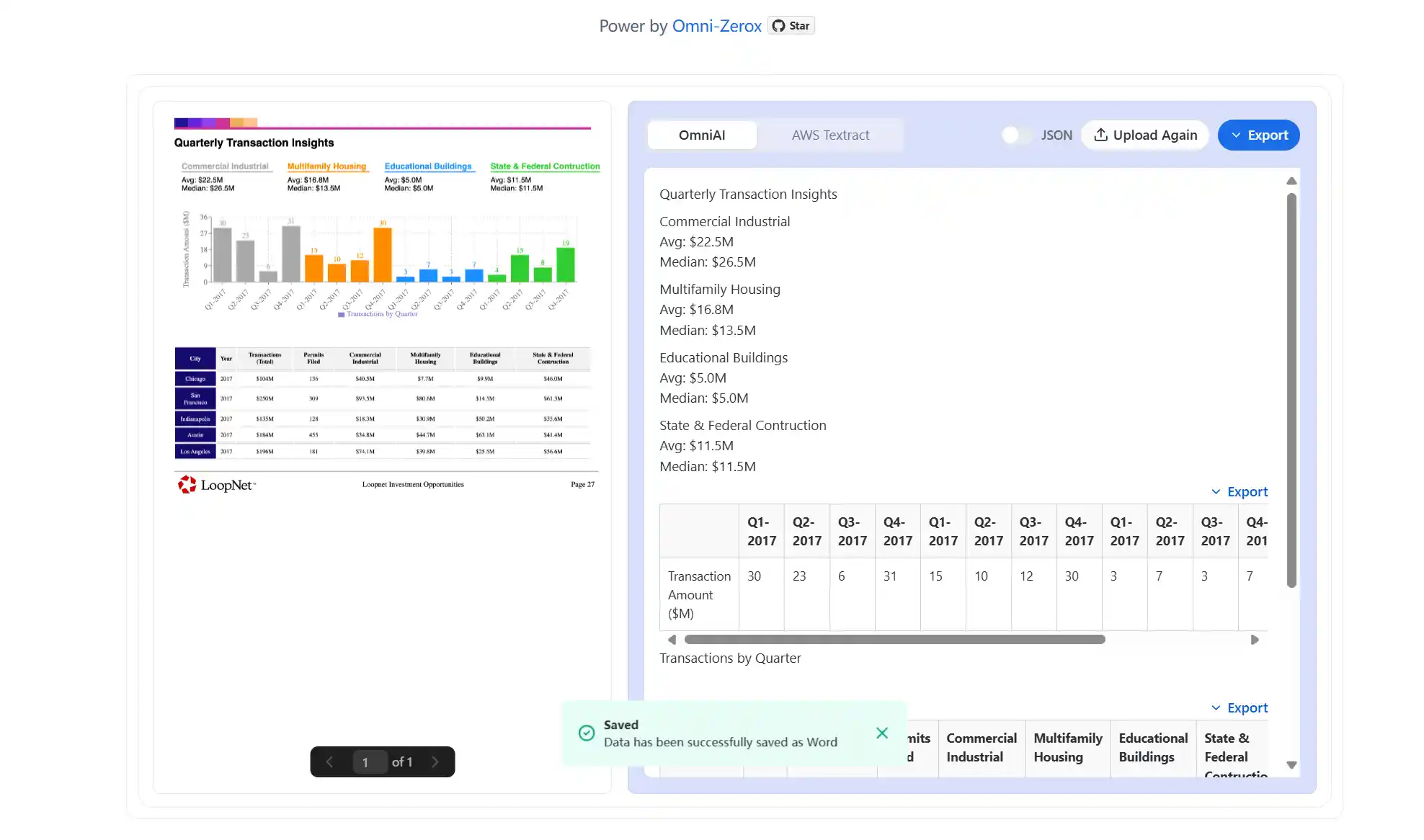
2. 功能特点
🔄 零样本OCR识别
Zerox基于GPT-4o-mini多模态模型,通过视觉-语言联合训练实现跨模态理解,无需预训练即可识别200+语言字符集,真正实现了开箱即用。
📑 多格式文件支持
支持包括PDF、DOCX、DOC、ODT、OTT、RTF、TXT、HTML、HTM、XML、WPS、WPD、XLS、XLSX、ODS、OTS、CSV、TSV、PPT、PPTX、ODP、OTP等20多种文件格式。
🧩 复杂布局处理能力
采用视觉分割网络(基于YOLOv9改进版) 定位表格/图表区域,精度达到98.2%,结合语义重建模块通过Transformer解码器还原单元格逻辑关系。支持多栏文本流重组,自动修复扫描件扭曲变形。
✍️ 手写体识别
对手写笔记、签名等内容的识别准确率高达90%以上,堪称”打工人救星”。
📊 Markdown格式输出
将识别结果转换为结构化Markdown格式,自动生成标题、列表、表格等元素,方便后续编辑和整理,较好地保持文档的视觉和结构完整性。
⚡ API接口与并发处理
提供API接口,便于开发者集成到自己的应用程序中,实现自动化、批量化的文档处理功能。支持并行处理多个页面,大幅提升工作效率。
3. 技术原理
Zerox的工作流程分为三个核心步骤:
文件转换:将用户提交的PDF、DOCX等格式的文件转换为一系列图像,便于后续模型对文字内容进行准确提取。
GPT-4o-mini模型识别:基于GPT-4o-mini模型对转换后的图像进行OCR识别。模型基于深度学习技术,对图像中的文字进行分析和识别,理解复杂的布局和格式,准确提取出文字内容。
结果转换与汇总:将每个图像的OCR识别结果转换成Markdown格式,将所有页面的Markdown结果汇总在一起,形成一个完整的Markdown文档。
对于复杂布局解析,Zerox采用了几项核心技术:视觉分割网络精准定位表格/图表区域;语义重建模块还原单元格逻辑关系;支持多栏文本流重组,自动修复扫描件扭曲变形。
对于正在寻找高效文档处理解决方案的用户和企业,Zerox提供了以下几个核心价值:
高精度识别:基于GPT-4o-mini模型,零样本处理复杂布局,准确率远超传统OCR工具
多格式支持:支持20多种文件格式,满足多样化需求
结构化输出:Markdown格式输出,便于后续编辑和内容管理
企业级集成:提供API接口和分布式处理框架,支持大规模应用
开源免费:MIT许可证,可自由使用和修改,避免商业OCR的高额授权费
建议企业优先试点合同自动化、医疗报告分析等高价值场景,短期可获得>300% ROI回报。
4.资源链接
- GitHub仓库:https://github.com/getomni-ai/zerox
- 在线体验Demo:https://getomni.ai/ocr-demo














