近日,面壁智能与清华大学深圳国际研究生院人机语音交互实验室(THUHCSI)联合推出 VoxCPM 语音生成基座模型。这款仅含 0.5B 参数的紧凑模型,在语音自然度、音色相似度及韵律表现力方面均达到了 SOTA 水平,甚至能够生成各种方言语音。
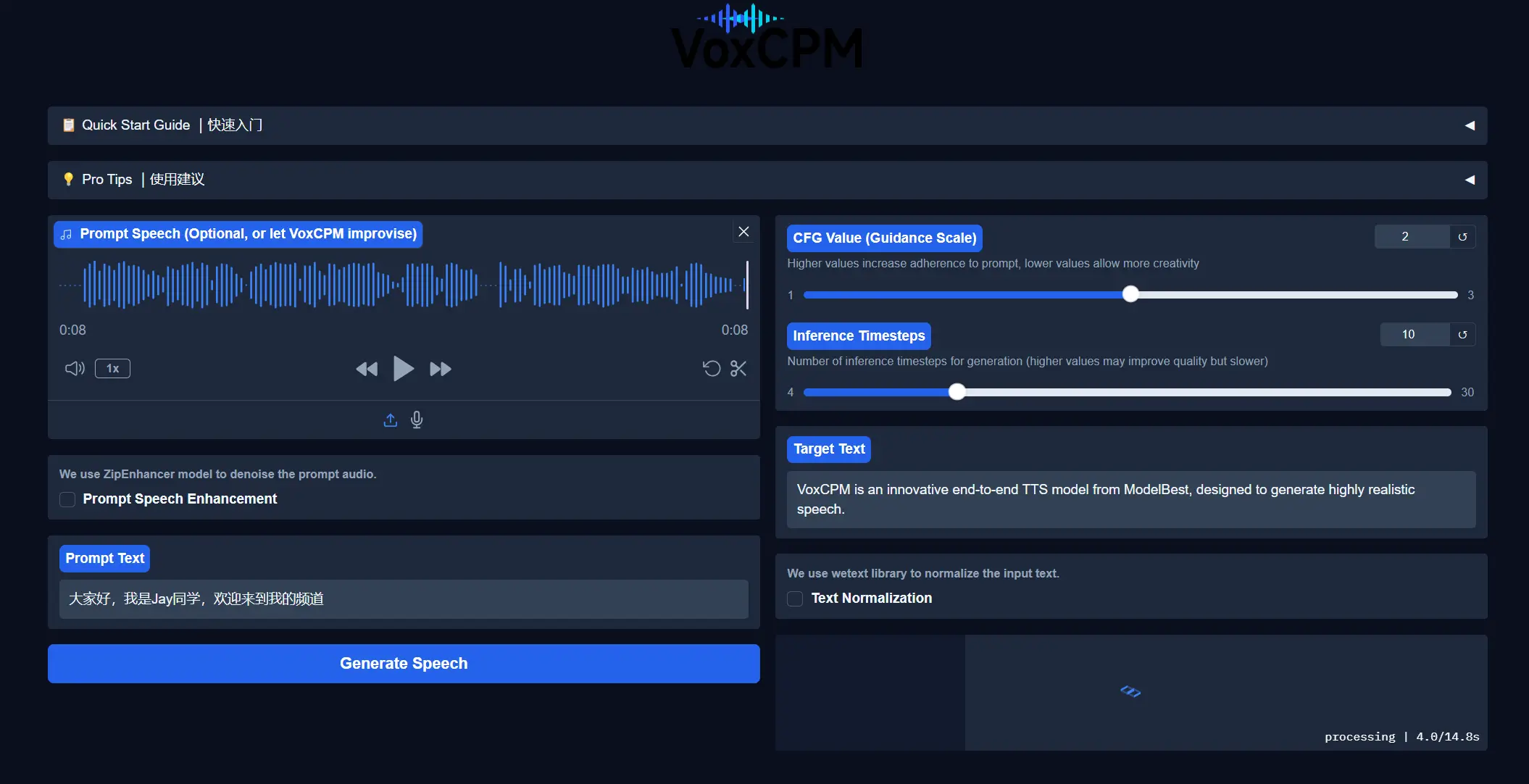
创新架构设计
VoxCPM 采用融合层次化语言建模和局部扩散生成的端到端 TTS 方案,与当前主流的离散声学词元方案(如 CosyVoice、FireRedTTS 及 SparkTTS)形成显著区别。该模型以 MiniCPM 4.0 文本基座模型为基础进行初始化,通过引入有限标量约束构建结构化的中间表征,实现了”语义-声学”生成过程的隐式解耦。
四大核心模块
局部音频编码模块 (LocEnc Module)
文本-语义语言模型 (Text-Semantic LM, TSLM)
残差声学语言模型 (Residual Acoustic LM, RALM)
局部扩散生成模块 (LocDiT Module)
权威评测领先
VoxCPM 在 Seed-TTS-EVAL 等权威语音合成评测榜单中均达到业界领先水平:
- 极低词错率:在正常样本和困难样本上均取得优异表现
- 顶尖音色相似度:在 Zero-shot 音色克隆任务中展示出顶尖性能
- 卓越推理效率:在一张 NVIDIA RTX 4090 显卡上实现 RTF ≈ 0.17 的高效推理速度
RTF(Real-Time Factor)= 模型生成音频时间 / 音频实际时长
「RTF < 0.2」属于极好水平,完全满足高质量实时交互需求
超拟人听觉体验
多样化语音生成
VoxCPM 生成的语音在情绪、音色、口音、停顿、韵律等方面与真人无异:
- 专业播报:字正腔圆的天气预报员播报
- 情感表达:英雄将领战前慷慨激昂地演讲
- 方言支持:流畅自然的各地方言生成(如河南话)
- 中英双语:支持中英文声音复刻与合成
特殊场景处理
- 公式符号音频合成:支持数学公式和特殊符号的准确读音(需关闭文本正则选项)
- 自定义读音纠正:通过音素标记替换实现发音修正(中文使用拼音,英文使用 ARPAbet)
开源生态与体验
VoxCPM 已在主流平台全面开源:
- GitHub:https://github.com/OpenBMB/VoxCPM
- Hugging Face:https://huggingface.co/openbmb/VoxCPM-0.5B
- ModelScope:https://modelscope.cn/models/OpenBMB/VoxCPM-0.5B
开发者可通过以下方式体验: